Nucleotide Sequence (with vector) for pF1KA0531
Download
>pF1KA0531 5984 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGCGGATCCA
GCCGAATGCAGCATCAAAGTGATGTGCCGGTTCCGGCCCCTCAACGAAGCGGAGATCCTC
CGCGGGGACAAATTCATCCCCAAATTTAAAGGCGATGAGACCGTGGTGATCGGGCAAGGG
AAGCCATATGTCTTCGACAGAGTGCTACCTCCCAACACGACCCAAGAGCAGGTTTACAAT
GCATGTGCGAAGCAAATTGTCAAAGATGTCCTTGAAGGTTATAACGGGACGATTTTTGCG
TATGGGCAGACTTCATCAGGAAAAACCCACACCATGGAGGGGAAGCTGCATGACCCCCAG
CTCATGGGGATCATCCCACGAATTGCCCATGATATCTTTGACCATATCTACTCCATGGAT
GAGAACCTGGAGTTTCACATAAAGGTTTCCTATTTTGAGATCTACTTGGACAAAATAAGG
GACTTACTTGATGTATCCAAGACCAACTTGGCTGTTCATGAAGATAAAAACAGAGTCCCG
TATGTAAAGGGGTGCACTGAGCGGTTTGTGTCGAGCCCTGAGGAAGTCATGGATGTAATA
GATGAAGGCAAAGCAAACCGACACGTGGCTGTGACAAACATGAATGAACACAGCTCTAGA
AGTCACAGTATCTTCCTGATAAATATTAAACAAGAGAATGTAGAGACTGAAAAAAAACTC
AGTGGGAAACTTTATTTGGTTGATTTGGCTGGGAGCGAAAAGGTCAGCAAAACTGGTGCC
GAGGGAGCTGTTCTTGACGAAGCTAAAAATATCAATAAGTCTTTGTCTGCTCTTGGAAAT
GTGATCTCTGCTTTGGCAGAAGGGACAAAAACACATGTGCCATACCGGGACAGCAAGATG
ACTCGGATTCTTCAGGACTCTTTGGGTGGGAACTGCAGAACCACCATCGTCATTTGCTGT
TCTCCTTCTGTCTTCAATGAGGCTGAGACCAAGTCCACACTGATGTTCGGACAGAGAGCT
AAGACCATCAAGAATACAGTCTCTGTGAACCTAGAACTGACAGCAGAAGAATGGAAGAAG
AAATATGAAAAAGAGAAAGAGAAAAACAAGACTTTGAAGAATGTTATCCAGCATCTGGAG
ATGGAGCTAAACAGGTGGAGGAATGGAGAAGCTGTGCCTGAGGATGAACAGATCAGTGCC
AAGGACCAGAAGAACCTGGAGCCTTGTGATAACACCCCCATCATAGACAATATTGCTCCT
GTTGTTGCTGGCATCTCTACAGAGGAGAAAGAGAAGTACGATGAGGAGATCTCCAGTCTC
TACAGACAACTGGATGACAAGGATGATGAAATTAACCAGCAGAGCCAGCTGGCTGAAAAG
CTGAAGCAACAGATGTTGGATCAGGATGAGCTTTTAGCTTCCACAAGAAGAGACTATGAG
AAGATACAGGAGGAGCTGACACGTCTCCAGATTGAAAATGAGGCAGCCAAGGATGAGGTG
AAAGAAGTTCTCCAGGCCCTGGAGGAGCTGGCTGTCAATTATGACCAGAAATCACAGGAA
GTGGAGGATAAGACCCGGGCCAATGAGCAGCTGACAGACGAGCTGGCCCAGAAAACGACT
ACATTGACAACCACACAGAGAGAGCTGAGCCAGCTACAAGAGCTTAGCAACCACCAGAAG
AAAAGGGCAACTGAGATCCTGAATTTGCTGTTGAAAGATCTGGGGGAGATAGGTGGAATT
ATTGGCACCAATGATGTGAAAACTTTGGCAGATGTGAATGGAGTCATTGAGGAGGAGTTT
ACCATGGCCCGCCTGTACATCAGCAAGATGAAGTCAGAGGTCAAGTCCCTGGTGAACCGC
AGCAAACAGCTCGAGAGCGCCCAGATGGACTCCAACAGGAAGATGAATGCCAGCGAGCGG
GAGCTGGCAGCCTGCCAGCTGCTCATCTCCCAGCACGAAGCCAAGATCAAGTCTCTGACA
GACTACATGCAGAACATGGAACAGAAGAGGAGGCAGCTAGAAGAGTCCCAGGACTCGCTC
AGCGAAGAGCTGGCAAAGCTCCGAGCCCAGGAAAAAATGCACGAAGTCAGCTTCCAGGAT
AAGGAGAAGGAACATCTGACGCGGTTGCAGGATGCTGAAGAAATGAAGAAGGCGCTGGAG
CAGCAGATGGAGAGCCACCGGGAAGCTCACCAGAAGCAGCTGTCCAGACTCCGAGACGAA
ATTGAGGAGAAGCAGAAAATCATTGATGAGATTCGGGATTTGAATCAGAAACTGCAACTG
GAACAGGAGAAGCTTAGTTCTGATTATAACAAGCTGAAAATAGAGGACCAAGAGAGAGAA
ATGAAGCTGGAAAAGCTCTTATTGCTCAACGATAAAAGGGAACAAGCCAGAGAAGACCTC
AAAGGGCTGGAGGAGACAGTGTCTAGAGAATTGCAGACACTGCACAACCTTCGGAAACTC
TTTGTCCAGGATCTGACCACCCGAGTTAAAAAAAGTGTGGAGTTGGACAACGATGATGGA
GGGGGCAGTGCTGCCCAGAAGCAGAAAATTTCCTTCTTGGAGAATAACCTGGAGCAGCTC
ACCAAAGTTCACAAGCAGCTGGTCCGGGACAACGCAGACCTGCGCTGTGAACTGCCCAAG
CTGGAGAAGCGGCTGCGTGCCACGGCGGAGCGCGTCAAGGCTCTGGAGAGCGCGCTGAAG
GAGGCCAAGGAGAACGCCATGCGGGACCGTAAGCGCTACCAGCAGGAGGTGGATCGTATC
AAGGAGGCCGTGCGGGCCAAGAACATGGCCAGAAGGGCCCATTCAGCCCAGATCGCCAAG
CCCATCCGCCCCGGACACTACCCGGCCTCATCTCCAACGGCCGTCCATGCCATTCGAGGG
GGAGGAGGCAGCTCTTCAAATTCCACTCACTACCAGAAAGTTTAAACGAATTCGAGCTCG
GTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAA
AGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCT
TGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTC
GCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTAC
CTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCAT
CCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCC
CTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCC
TCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATC
TGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTT
GAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTAT
GACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAG
GGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGAC
GAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGAC
GTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTC
CTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGG
CTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAG
CGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCAT
CAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAG
GATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGC
TTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCG
TTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTG
CTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAG
TTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATC
AGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAA
CATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTT
TTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTG
GCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCG
CTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAG
CGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTC
CAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAA
CTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGG
TAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCC
TAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTAC
CTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGG
TTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTT
GATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGT
CATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAAC
GCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGA
TTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAAT
TTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCT
GCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCC
ACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTC
CGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGG
TCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCC
GAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGT
AGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTT
TTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATT
TGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCA
GGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTC
TTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 2871 bp
Length: 2871 bp Restriction map B
Restriction map B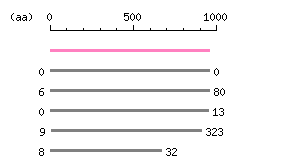
 more Linker info
more Linker info
{kind=link}