


-
SpecieshumanProduct IDFXC01100Cloning SiteSgfI-PmeISymbolMARCH6Descriptionmembrane-associated ring finger (C3HC4) 6, E3 ubiquitin protein ligase, transcript variant 1
 Length: 2730 bp
Length: 2730 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 910 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
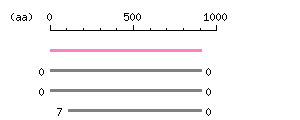
Entry Exp ID% symbol CCDS34135.1 0 100.0 MARCH6 CCDS59487.1 0 94.6 MARCH6 CCDS59488.1 0 100.0 MARCH6
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR018957 9 55 PF00097 Zinc finger HMMSmart IPR011016 8 56 SM00744 Zinc finger ProfileScan IPR011016 1 62 PS51292 Zinc finger
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 93 WFHYTLVAFAWLGVVPLTACRIY 115 PRIMARY 23 2 145 QGCFVVTCTLCAFISLVWLREQI 167 PRIMARY 23 3 281 DGSLVFLEHVFWVVSLNTLFILV 303 PRIMARY 23 4 333 LITTIVGYILLAITLIICHGLAT 355 PRIMARY 23 5 374 KVSLLVVVEIGVFPLICGWWLDI 396 PRIMARY 23 6 428 GMVYVFYFASFILLLREVLRPGV 450 PRIMARY 23 7 480 FILSVIVFGSIVLLMLWLPIRII 502 PRIMARY 23 8 522 VSELSLELLLLQVVLPALLEQGH 544 SECONDARY 23 9 632 RIFLLIVFMCITLLIASLICLTL 654 PRIMARY 23 10 677 TAACGLYVCWLTIRAVTVMVAWM 699 PRIMARY 23 11 720 TLIVAVLLAGVVPLLLGLLFELV 742 PRIMARY 23 12 761 QDWALGVLHAKIIAAITLMGPQW 783 SECONDARY 23 13 814 ISVLLLSLCVPYVIASGVVPLLG 836 PRIMARY 23 14 849 IYPFLLMVVVLMAILSFQVRQF 870 PRIMARY 22
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_005876 910 613297 100.0 100.0 XP_011512234 842 613297 100.0 92.5 NP_001257589 862 613297 94.6 100.0 NP_001257590 805 613297 100.0 87.7 XP_011512236 791 613297 99.3 84.5 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KA0597 Download>KIAA0597 2730 bp ATGGACACCGCGGAGGAAGACATATGTAGAGTGTGTCGGTCAGAAGGAACACCTGAGAAA CCGCTTTATCATCCTTGTGTATGTACTGGCAGTATTAAGTTTATCCATCAAGAATGCTTA GTTCAATGGCTGAAACACAGTCGAAAAGAATACTGTGAATTATGCAAGCACAGATTTGCT TTTACACCAATTTATTCTCCAGATATGCCTTCACGGCTTCCAATTCAAGACATATTTGCT GGACTGGTTACAAGTATTGGCACTGCAATACGATATTGGTTTCATTATACACTTGTGGCC TTTGCATGGTTGGGAGTTGTTCCTCTTACAGCATGCCGCATCTACAAGTGCTTGTTTACT GGCTCCGTGAGCTCACTACTGACGCTGCCATTAGATATGCTGTCAACGGAAAATTTGTTG GCAGATTGTTTGCAGGGTTGTTTTGTGGTGACGTGCACACTGTGTGCATTCATCAGCCTG GTGTGGTTGAGAGAGCAGATAGTCCATGGGGGAGCACCAATTTGGTTGGAGCATGCTGCC CCACCGTTCAATGCTGCGGGGCATCACCAAAATGAGGCTCCAGCAGGAGGAAATGGTGCA GAAAATGTTGCTGCTGATCAGCCTGCTAACCCACCAGCTGAGAACGCAGTGGTGGGGGAA AACCCTGATGCCCAGGATGACCAGGCAGAAGAGGAGGAGGAGGACAATGAGGAGGAAGAT GACGCTGGTGTGGAGGATGCGGCAGATGCTAATAACGGAGCCCAGGATGACATGAATTGG AATGCTTTAGAATGGGACCGAGCTGCTGAAGAGCTTACATGGGAAAGAATGCTAGGACTT GATGGATCACTAGTTTTTCTGGAACATGTCTTCTGGGTGGTATCTTTAAATACACTGTTC ATTCTTGTTTTTGCATTTTGCCCTTACCATATTGGTCATTTCTCCCTTGTTGGTTTGGGA TTTGAAGAACACGTCCAAGCATCTCATTTTGAAGGCCTAATCACAACCATAGTTGGGTAT ATACTTTTAGCAATAACACTGATAATTTGTCATGGCTTGGCAACTCTTGTGAAATTTCAT AGATCTCGTCGCTTACTGGGAGTCTGCTATATTGTTGTTAAGGTCTCTTTGTTAGTGGTG GTAGAAATTGGAGTATTCCCTCTCATTTGTGGTTGGTGGCTGGATATCTGTTCCTTGGAA ATGTTTGATGCTACTCTGAAAGATCGAGAACTGAGCTTTCAGTCGGCTCCAGGTACTACC ATGTTTCTGCATTGGCTAGTGGGAATGGTATATGTCTTCTACTTTGCCTCCTTCATTCTA CTACTGAGAGAGGTACTTCGACCTGGTGTCCTGTGGTTTCTAAGGAATTTGAATGATCCA GATTTCAATCCAGTACAGGAAATGATCCATTTGCCAATATATAGGCATCTCCGAAGATTT ATTTTGTCAGTGATTGTCTTTGGCTCCATTGTCCTCCTGATGCTTTGGCTTCCTATACGT ATAATTAAGAGTGTGCTGCCTAATTTTCTTCCATACAATGTCATGCTCTACAGTGATGCT CCAGTGAGTGAACTGTCCCTCGAGCTGCTTCTGCTTCAGGTTGTCTTGCCAGCATTACTC GAACAGGGACACACGAGGCAGTGGCTGAAGGGGCTGGTGCGAGCGTGGACTGTGACCGCC GGATACTTGCTGGATCTTCATTCTTATTTATTGGGAGACCAGGAAGAAAATGAAAACAGT GCAAATCAACAAGTTAACAATAATCAGCATGCTCGAAATAACAACGCTATTCCTGTGGTG GGAGAAGGCCTTCATGCAGCCCACCAAGCCATACTCCAGCAGGGAGGGCCTGTTGGCTTT CAGCCTTACCGCCGACCTTTAAATTTTCCACTCAGGATATTTCTGTTGATTGTCTTCATG TGTATAACATTACTGATTGCCAGCCTCATCTGCCTTACTTTACCAGTATTTGCTGGCCGT TGGTTAATGTCGTTTTGGACGGGGACTGCCAAAATCCATGAGCTCTACACAGCTGCTTGT GGTCTCTATGTTTGCTGGCTAACCATAAGGGCTGTGACGGTGATGGTGGCATGGATGCCT CAGGGACGCAGAGTGATCTTCCAGAAGGTTAAAGAGTGGTCTCTCATGATCATGAAGACT TTGATAGTTGCGGTGCTGTTGGCTGGAGTTGTCCCTCTCCTTCTGGGGCTCCTGTTTGAG CTGGTCATTGTGGCTCCCCTGAGGGTTCCCTTGGATCAGACTCCTCTTTTTTATCCATGG CAGGACTGGGCACTTGGAGTCCTGCATGCCAAAATCATTGCAGCTATAACATTGATGGGT CCTCAGTGGTGGTTGAAAACTGTAATTGAACAGGTTTACGCAAATGGCATCCGGAACATT GACCTTCACTATATTGTTCGTAAACTGGCAGCTCCCGTGATCTCTGTGCTGTTGCTTTCC CTGTGTGTACCTTATGTCATAGCTTCTGGTGTTGTTCCTTTACTAGGTGTTACTGCGGAA ATGCAAAACTTAGTCCATCGGCGGATTTATCCATTTTTACTGATGGTCGTGGTATTGATG GCAATTTTGTCCTTCCAAGTCCGCCAGTTTAAGCGCCTTTATGAACATATTAAAAATGAC AAGTACCTTGTGGGTCAACGACTCGTGAACTACGAACGGAAATCTGGCAAACAAGGCTCA TCTCCACCACCTCCACAGTCATCCCAAGAA
Cloned ORF protein sequence for pF1KA0597 Download>KIAA0597 910 aa MDTAEEDICRVCRSEGTPEKPLYHPCVCTGSIKFIHQECLVQWLKHSRKEYCELCKHRFA FTPIYSPDMPSRLPIQDIFAGLVTSIGTAIRYWFHYTLVAFAWLGVVPLTACRIYKCLFT GSVSSLLTLPLDMLSTENLLADCLQGCFVVTCTLCAFISLVWLREQIVHGGAPIWLEHAA PPFNAAGHHQNEAPAGGNGAENVAADQPANPPAENAVVGENPDAQDDQAEEEEEDNEEED DAGVEDAADANNGAQDDMNWNALEWDRAAEELTWERMLGLDGSLVFLEHVFWVVSLNTLF ILVFAFCPYHIGHFSLVGLGFEEHVQASHFEGLITTIVGYILLAITLIICHGLATLVKFH RSRRLLGVCYIVVKVSLLVVVEIGVFPLICGWWLDICSLEMFDATLKDRELSFQSAPGTT MFLHWLVGMVYVFYFASFILLLREVLRPGVLWFLRNLNDPDFNPVQEMIHLPIYRHLRRF ILSVIVFGSIVLLMLWLPIRIIKSVLPNFLPYNVMLYSDAPVSELSLELLLLQVVLPALL EQGHTRQWLKGLVRAWTVTAGYLLDLHSYLLGDQEENENSANQQVNNNQHARNNNAIPVV GEGLHAAHQAILQQGGPVGFQPYRRPLNFPLRIFLLIVFMCITLLIASLICLTLPVFAGR WLMSFWTGTAKIHELYTAACGLYVCWLTIRAVTVMVAWMPQGRRVIFQKVKEWSLMIMKT LIVAVLLAGVVPLLLGLLFELVIVAPLRVPLDQTPLFYPWQDWALGVLHAKIIAAITLMG PQWWLKTVIEQVYANGIRNIDLHYIVRKLAAPVISVLLLSLCVPYVIASGVVPLLGVTAE MQNLVHRRIYPFLLMVVVLMAILSFQVRQFKRLYEHIKNDKYLVGQRLVNYERKSGKQGS SPPPPQSSQE
Nucleotide Sequence (with vector) for pF1KA0597 Download>pF1KA0597 5843 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGACACCGCG GAGGAAGACATATGTAGAGTGTGTCGGTCAGAAGGAACACCTGAGAAACCGCTTTATCAT CCTTGTGTATGTACTGGCAGTATTAAGTTTATCCATCAAGAATGCTTAGTTCAATGGCTG AAACACAGTCGAAAAGAATACTGTGAATTATGCAAGCACAGATTTGCTTTTACACCAATT TATTCTCCAGATATGCCTTCACGGCTTCCAATTCAAGACATATTTGCTGGACTGGTTACA AGTATTGGCACTGCAATACGATATTGGTTTCATTATACACTTGTGGCCTTTGCATGGTTG GGAGTTGTTCCTCTTACAGCATGCCGCATCTACAAGTGCTTGTTTACTGGCTCCGTGAGC TCACTACTGACGCTGCCATTAGATATGCTGTCAACGGAAAATTTGTTGGCAGATTGTTTG CAGGGTTGTTTTGTGGTGACGTGCACACTGTGTGCATTCATCAGCCTGGTGTGGTTGAGA GAGCAGATAGTCCATGGGGGAGCACCAATTTGGTTGGAGCATGCTGCCCCACCGTTCAAT GCTGCGGGGCATCACCAAAATGAGGCTCCAGCAGGAGGAAATGGTGCAGAAAATGTTGCT GCTGATCAGCCTGCTAACCCACCAGCTGAGAACGCAGTGGTGGGGGAAAACCCTGATGCC CAGGATGACCAGGCAGAAGAGGAGGAGGAGGACAATGAGGAGGAAGATGACGCTGGTGTG GAGGATGCGGCAGATGCTAATAACGGAGCCCAGGATGACATGAATTGGAATGCTTTAGAA TGGGACCGAGCTGCTGAAGAGCTTACATGGGAAAGAATGCTAGGACTTGATGGATCACTA GTTTTTCTGGAACATGTCTTCTGGGTGGTATCTTTAAATACACTGTTCATTCTTGTTTTT GCATTTTGCCCTTACCATATTGGTCATTTCTCCCTTGTTGGTTTGGGATTTGAAGAACAC GTCCAAGCATCTCATTTTGAAGGCCTAATCACAACCATAGTTGGGTATATACTTTTAGCA ATAACACTGATAATTTGTCATGGCTTGGCAACTCTTGTGAAATTTCATAGATCTCGTCGC TTACTGGGAGTCTGCTATATTGTTGTTAAGGTCTCTTTGTTAGTGGTGGTAGAAATTGGA GTATTCCCTCTCATTTGTGGTTGGTGGCTGGATATCTGTTCCTTGGAAATGTTTGATGCT ACTCTGAAAGATCGAGAACTGAGCTTTCAGTCGGCTCCAGGTACTACCATGTTTCTGCAT TGGCTAGTGGGAATGGTATATGTCTTCTACTTTGCCTCCTTCATTCTACTACTGAGAGAG GTACTTCGACCTGGTGTCCTGTGGTTTCTAAGGAATTTGAATGATCCAGATTTCAATCCA GTACAGGAAATGATCCATTTGCCAATATATAGGCATCTCCGAAGATTTATTTTGTCAGTG ATTGTCTTTGGCTCCATTGTCCTCCTGATGCTTTGGCTTCCTATACGTATAATTAAGAGT GTGCTGCCTAATTTTCTTCCATACAATGTCATGCTCTACAGTGATGCTCCAGTGAGTGAA CTGTCCCTCGAGCTGCTTCTGCTTCAGGTTGTCTTGCCAGCATTACTCGAACAGGGACAC ACGAGGCAGTGGCTGAAGGGGCTGGTGCGAGCGTGGACTGTGACCGCCGGATACTTGCTG GATCTTCATTCTTATTTATTGGGAGACCAGGAAGAAAATGAAAACAGTGCAAATCAACAA GTTAACAATAATCAGCATGCTCGAAATAACAACGCTATTCCTGTGGTGGGAGAAGGCCTT CATGCAGCCCACCAAGCCATACTCCAGCAGGGAGGGCCTGTTGGCTTTCAGCCTTACCGC CGACCTTTAAATTTTCCACTCAGGATATTTCTGTTGATTGTCTTCATGTGTATAACATTA CTGATTGCCAGCCTCATCTGCCTTACTTTACCAGTATTTGCTGGCCGTTGGTTAATGTCG TTTTGGACGGGGACTGCCAAAATCCATGAGCTCTACACAGCTGCTTGTGGTCTCTATGTT TGCTGGCTAACCATAAGGGCTGTGACGGTGATGGTGGCATGGATGCCTCAGGGACGCAGA GTGATCTTCCAGAAGGTTAAAGAGTGGTCTCTCATGATCATGAAGACTTTGATAGTTGCG GTGCTGTTGGCTGGAGTTGTCCCTCTCCTTCTGGGGCTCCTGTTTGAGCTGGTCATTGTG GCTCCCCTGAGGGTTCCCTTGGATCAGACTCCTCTTTTTTATCCATGGCAGGACTGGGCA CTTGGAGTCCTGCATGCCAAAATCATTGCAGCTATAACATTGATGGGTCCTCAGTGGTGG TTGAAAACTGTAATTGAACAGGTTTACGCAAATGGCATCCGGAACATTGACCTTCACTAT ATTGTTCGTAAACTGGCAGCTCCCGTGATCTCTGTGCTGTTGCTTTCCCTGTGTGTACCT TATGTCATAGCTTCTGGTGTTGTTCCTTTACTAGGTGTTACTGCGGAAATGCAAAACTTA GTCCATCGGCGGATTTATCCATTTTTACTGATGGTCGTGGTATTGATGGCAATTTTGTCC TTCCAAGTCCGCCAGTTTAAGCGCCTTTATGAACATATTAAAAATGACAAGTACCTTGTG GGTCAACGACTCGTGAACTACGAACGGAAATCTGGCAAACAAGGCTCATCTCCACCACCT CCACAGTCATCCCAAGAAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAG TCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTT GGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTT GAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGC CCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGC GTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTG CGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCG GCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCC TGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGA TCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCA GGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATC GGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTC AAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGG CTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGG GACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCT GCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCT ACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAA GCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAA CTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGC GATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGT GGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCT GAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCC GATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGG GGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAAT ACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCA AAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCC TGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATA AAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCC GCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTC ACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGA ACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCC GGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAG GTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAG GACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAG CTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCA GATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGA CGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGAT CTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGC TGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCC TGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCA GTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCG TTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAG CCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCT TTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCC TGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCG TAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAA TAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGA ACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGC CCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGG CCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATA CATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}