Nucleotide Sequence (with vector) for pF1KA0651
Download
>pF1KA0651 6353 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGCCCAGGCCC
CAAGGAGGCCCTCTTCCTGCAGATCCGAGAAGGACTGGACACCTTTCTGGGACTGGACAC
CAGGGTGGCTACGCCTCCCGGCTGGATCAGGATTCCTGTCATCCATCTGCTGGCCCTTTG
GACCACTCGGCCACTGGCATGCTTTCCAAGTCTGTACCCGTGAGTGGCATCAACTGTCTC
TTGGACCGTTCGGATACAGATGGGAATGTATCCCAGTCCTCTGCCATTGACCTCAGGAAA
CGCTGCAGCCAGCTGGAAGGACATTCAGGTACCCGGGTAGGCTCCTCCCTGCGACAGACC
TTCAGCTTCCTCTCGGGCATGACCGGAAAGGCCAAGACCCGGGAAAAGGAGAAGATGAAG
GAAGCCAAGGATGCCCGCTATACCAATGGGCACCTCTTCACCACCATTTCAGTTTCAGGC
ATGACCATGTGCTATGCCTGTAACAAGAGCATCACAGCCAAGGAAGCCCTCATCTGCCCA
ACCTGCAATGTGACTATCCACAACCGCTGTAAAGACACCCTCGCCAACTGTACCAAGGTC
AAGCAGAAGCAACAGAAAGCGGCCCTGCTGAAGAACAACACCGCCTTGCAGTCCGTTTCT
CTTCGAAGTAAGACAACCATCCGGGAGCGGCCAAGCTCGGCCATCTACCCCTCCGACAGC
TTCCGGCAGTCCCTCCTGGGCTCCCGCCGTGGCCGCTCCTCCTTGTCTTTAGCCAAGAGT
GTTTCTACCACCAACATTGCTGGACATTTCAATGATGAGTCTCCCCTGGGGCTGCGCCGG
ATCCTCTCACAGTCCACAGACTCCCTCAACATGCGGAACCGAACCCTATCCGTGGAATCC
CTCATTGACGAAGAGGTAATCTACAGTGAGCTGATGAGTGACTTTGAGATGGATGAGAAG
GACTTTGCAGCTGACTCTTGGAGTCTTGCTGTGGACAGCAGCTTCCTGCAGCAGCATAAA
AAGGAGGTGATGAAGCAGCAAGATGTCATCTATGAGCTAATCCAGACAGAGCTGCACCAT
GTGAGGACACTGAAGATCATGACCCGCCTCTTCCGCACGGGGATGCTGGAAGAGCTACAC
TTGGAGCCAGGAGTGGTCCAGGGCCTGTTCCCCTGCGTGGACGAGCTCAGTGACATCCAT
ACACGCTTCCTCAGCCAGCTATTAGAACGCCGACGCCAGGCCCTGTGCCCTGGCAGCACC
CGGAACTTTGTCATCCATCGCTTGGGTGATCTGCTCATCAGCCAGTTCTCAGGTCCTAGT
GCGGAGCAGATGTGTAAGACCTACTCGGAGTTCTGCAGCCGCCACAGCAAGGCCTTAAAG
CTCTATAAGGAGCTGTACGCCCGAGACAAACGCTTCCAGCAATTCATCCGGAAAGTGACC
CGCCCCGCCGTGCTCAAGCGGCACGGGGTACAGGAGTGCATCCTGCTGGTGACTCAGCGC
ATCACCAAGTACCCGTTACTCATCAGCCGCATCCTGCAGCATTCCCACGGGATCGAGGAG
GAGCGCCAGGACCTGACCACAGCACTGGGGCTAGTGAAGGAGCTGCTGTCCAATGTGGAC
GAGGGTATTTATCAGCTGGAGAAAGGGGCCCGTCTGCAGGAGATCTACAACCGCATGGAC
CCTCGGGCCCAAACCCCAGTGCCTGGCAAGGGCCCCTTTGGCCGAGAGGAACTTCTGAGG
CGCAAACTCATCCACGATGGCTGCCTGCTCTGGAAGACAGCGACGGGGCGCTTCAAAGAT
GTGCTAGTGCTGCTGATGACAGATGTACTGGTGTTTCTCCAGGAAAAGGACCAGAAGTAC
ATCTTTCCTACCCTGGACAAGCCTTCAGTGGTATCGCTGCAGAATCTAATCGTACGAGAC
ATTGCCAACCAGGAGAAAGGGATGTTTCTGATCAGCGCAGCCCCACCTGAGATGTACGAG
GTGCACACAGCATCCCGGGATGACCGGAGCACCTGGATCCGGGTCATTCAGCAGAGCGTG
CGCACATGCCCATCCAGGGAGGACTTCCCCCTGATTGAGACAGAGGATGAGGCTTACCTG
CGGCGAATTAAGATGGAGTTGCAGCAGAAGGACCGGGCACTGGTGGAGCTGCTGCGAGAG
AAGGTCGGGCTGTTTGCTGAGATGACCCATTTCCAGGCCGAAGAGGATGGTGGCAGTGGG
ATGGCCCTGCCCACCCTGCCCAGGGGCCTTTTCCGCTCTGAGTCCCTTGAGTCCCCTCGT
GGCGAGCGGCTGCTGCAGGATGCCATCCGTGAGGTGGAGGGTCTGAAAGACCTGCTGGTG
GGGCCAGGAGTGGAACTGCTCTTGACACCCCGAGAGCCAGCCCTGCCCTTGGAACCAGAC
AGCGGTGGTAACACGAGTCCTGGGGTCACTGCCAATGGTGAGGCCAGAACCTTCAATGGC
TCCATTGAACTCTGCAGAGCTGACTCAGACTCTAGCCAGAGGGATCGAAATGGAAATCAG
CTGAGATCACCGCAAGAGGAGGCGTTACAGCGATTGGTCAATCTCTATGGACTTCTACAT
GGCCTACAGGCAGCTGTGGCCCAGCAGGACACTCTGATGGAAGCCCGGTTCCCTGAGGGC
CCTGAGCGGCGGGAGAAGCTGTGCCGAGCCAACTCTCGGGATGGGGAGGCTGGCAGGGCT
GGGGCTGCCCCTGTGGCCCCTGAAAAGCAGGCCACGGAACTGGCATTACTGCAGCGGCAA
CATGCGCTGCTGCAGGAGGAGCTACGGCGCTGCCGGCGGCTAGGTGAAGAACGGGCAACC
GAAGCTGGCAGCCTGGAGGCCCGGCTCCGGGAGAGTGAGCAGGCCCGGGCACTGCTGGAG
CGTGAGGCCGAAGAGGCTCGAAGGCAGCTGGCCGCCCTGGGCCAGACCGAGCCACTCCCA
GCTGAGGCCCCCTGGGCCCGCAGACCTGTGGATCCTCGGCGGCGCAGCCTCCCCGCAGGC
GATGCCCTGTACTTGAGTTTCAACCCCCCACAGCCCAGCCGAGGCACTGACCGCCTGGAT
CTACCTGTCACTACTCGCTCTGTCCATCGAAACTTTGAGGACCGAGAGAGGCAGGAACTG
GGGAGCCCCGAAGAGCGGCTGCAAGACAGCAGTGACCCTGACACTGGCAGCGAGGAGGAA
GGTAGCAGCCGTCTGTCTCCGCCCCACAGTCCACGAGACTTTACCAGAATGCAGGACATC
CCGGAGGAGACGGAGAGCCGCGACGGGGAGGCTGTAGCCTCCGAGAGCGTTTAAACGAAT
TCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGC
TGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGC
ATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTAT
ATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACT
GCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCT
GACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCT
TTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCT
GGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCG
CCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTT
CGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTA
TTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTG
TCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAA
CTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCT
GTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGG
CAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCA
ATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACAT
CGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGAC
GAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCG
GATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAA
AATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAG
GACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGC
TTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTT
CTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCA
ACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGC
AGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTT
GCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAG
TCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTC
CCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCC
TTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGT
CGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTT
ATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGC
AGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAA
GTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAA
GCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGG
TAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGA
AGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGG
GATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAA
TACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGC
TTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATAC
GGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTAC
CTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTAT
GGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCA
CGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACG
CAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGA
CCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCA
TGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGG
CCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGG
GAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCAT
AAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTC
TACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 3240 bp
Length: 3240 bp Restriction map B
Restriction map B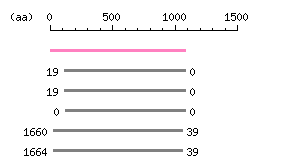

 more Linker info
more Linker info
{kind=link}