Nucleotide Sequence (with vector) for pF1KSDA0842
Download
>pF1KSDA0842 6196 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGAGCCGGGGGAGGTGAAGGACCGGATCCTGGAGAACATCTCGCTGTCGGTG
AAGAAGTTGCAGAGCTATTTTGCTGCATGTGAGGATGAGATCCCTGCCATCCGGAACCAT
GACAAGGTCCTACAGCGTCTGTGTGAGCACCTGGACCACGCCCTGCTGTACGGACTGCAA
GACCTCTCCTCTGGCTACTGGGTGCTCGTGGTGCATTTTACTCGGAGAGAGGCCATCAAG
CAGATCGAGGTGCTGCAGCACGTGGCCACCAACCTGGGGCGCAGCCGTGCCTGGCTGTAC
CTGGCCCTCAACGAGAACTCCTTGGAGAGCTACCTGCGGTTGTTCCAGGAGAACCTGGGC
CTGCTGCATAAGTACTACGTCAAGAATGCCCTGGTCTGCAGCCACGATCACCTGACGCTC
TTCCTGACCTTGGTGTCCGGGCTAGAGTTCATTCGTTTCGAGCTGGATCTGGATGCCCCT
TACCTAGACCTGGCCCCCTACATGCCCGACTACTACAAACCTCAGTACCTGCTGGACTTT
GAAGACCGCCTTCCCAGCTCGGTCCACGGCTCAGACAGTCTGTCCCTCAACTCTTTCAAC
TCCGTCACCTCCACCAACCTGGAGTGGGATGACAGTGCGATTGCCCCATCTAGTGAGGAT
TATGATTTTGGAGATGTGTTTCCAGCAGTGCCGTCTGTACCCAGCACAGACTGGGAAGAT
GGAGACCTCACAGACACGGTCAGTGGTCCCCGCTCCACAGCCTCCGACCTGACCAGCAGC
AAGGCCTCCACCAGGAGCCCCACCCAGCGCCAGAACCCCTTCAACGAGGAGCCGGCAGAG
ACTGTGTCCTCCTCTGACACCACCCCCGTGCACACCACCTCTCAGGAGAAGGAGGAGGCC
CAGGCCCTGGACCCGCCGGATGCCTGCACGGAGCTCGAGGTCATCAGGGTCACCAAGAAG
AAGAAAATTGGCAAGAAGAAAAAGAGCAGATCAGATGAGGAGGCAAGTCCACTCCACCCC
GCCTGCAGCCAGAAGAAATGTGCCAAGCAGGGGGACGGTGACAGCCGCAACGGCAGCCCA
AGCCTTGGGCGGGACTCGCCAGACACTATGCTTGCCTCCCCCCAGGAGGAGGGAGAGGGG
CCGAGCAGCACCACGGAGAGCAGCGAGCGCTCCGAGCCGGGCCTGCTGATCCCTGAGATG
AAGGACACCTCCATGGAGCGCTTGGGGCAGCCCCTGAGCAAGGTTATCGACCAGCTCAAC
GGGCAGCTGGACCCCAGCACCTGGTGCTCCCGTGCTGAGCCCCCAGACCAGTCCTTTCGG
ACCGGCTCTCCCGGGGATGCCCCGGAGAGGCCGCCGCTTTGCGACTTTAGTGAGGGGCTT
TCAGCCCCAATGGACTTCTACCGCTTTACCGTCGAGAGTCCAAGCACTGTTACATCAGGT
GGCGGCCACCATGACCCTGCAGGGCTTGGCCAACCGCTGCATGTTCCTAGTAGCCCTGAG
GCTGCTGGCCAAGAAGAAGAGGGAGGAGGAGGAGAGGGACAGACGCCTCGGCCCCTAGAG
GATACCACGAGGGAGGCTCAGGAGCTGGAGGCCCAGCTGTCCCTGGTCAGGGAGGGGCCT
GTGTCTGAGCCAGAGCCTGGGACCCAGGAGGTTCTCTGCCAGCTCAAGCGAGACCAGCCC
AGCCCGTGTCTGAGTAGCGCTGAGGATTCTGGGGTGGATGAGGGACAGGGGAGCCCTTCG
GAGATGGTCCATTCCTCGGAGTTCAGAGTAGACAACAATCACCTGCTCCTGCTCATGATC
CACGTGTTCCGAGAAAACGAAGAGCAGCTGTTCAAAATGATCCGGATGAGCACCGGGCAC
ATGGAGGGCAACCTGCAGCTGCTGTACGTGCTGCTCACAGACTGCTATGTCTACCTGCTC
CGGAAAGGGGCCACAGAGAAGCCATACCTGGTGGAAGAGGCCGTTTCTTACAATGAACTT
GACTATGTGTCGGTTGGCCTTGACCAGCAGACGGTGAAGCTGGTGTGCACCAACCGCAGG
AAGCAGTTTCTGCTGGACACGGCTGATGTGGCGCTGGCTGAGTTCTTTTTGGCTTCTTTG
AAGTCAGCCATGATCAAAGGCTGTCGAGAACCTCCCTACCCCAGCATCCTGACGGATGCC
ACCATGGAGAAGCTGGCACTGGCCAAATTTGTGGCCCAAGAATCGAAGTGTGAGGCATCT
GCTGTCACCGTGCGCTTCTACGGCCTTGTGCACTGGGAGGACCCCACAGACGAGTCCCTG
GGCCCCACGCCCTGCCACTGCTCACCCCCCGAGGGCACCATCACCAAAGAAGGCATGCTG
CACTACAAGGCGGGCACCTCCTACCTGGGCAAGGAACACTGGAAGACGTGCTTCGTGGTG
CTCAGCAACGGGATCCTCTACCAGTACCCGGACCGCACCGACGTCATCCCTCTGCTCTCG
GTGAACATGGGGGGGGAGCAGTGCGGTGGCTGCCGGAGAGCCAACACCACGGATCGGCCC
CACGCCTTCCAGGTCATTCTCTCCGACCGGCCCTGCCTGGAGCTAAGTGCCGAGAGCGAG
GCCGAGATGGCCGAGTGGATGCAGCATCTCTGCCAGGCTGTGTCCAAAGGGGTCATCCCC
CAGGGCGTAGCTCCCAGCCCCTGCATACCCTGCTGCCTGGTCCTCACGGATGACCGCCTC
TTTACGTGCCATGAGGATTGCCAGACCAGCTTCTTCCGCTCTTTGGGCACAGCCAAGCTG
GGCGACATCAGCGCCGTCTCCACCGAGCCGGGCAAGGAGTACTGCGTCTTGGAGTTCTCC
CAGGACAGCCAGCAGCTCCTCCCGCCCTGGGTCATCTACCTGAGCTGCACTTCTGAACTG
GACCGATTGCTGTCTGCACTGAACTCTGGGTGGAAAACCATCTATCAGGTGGACCTCCCC
CACACGGCGATCCAGGAAGCCTCCAACAAGAAGAAATTCGAGGATGCCTTGAGCCTCATC
CACAGCGCCTGGCAGCGGAGCGACAGTCTCTGCCGCGGCCGAGCCTCCCGAGACCCCTGG
TGCTACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGC
AGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGC
CACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTT
TTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAG
CTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCT
TGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGC
TTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGA
GCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTA
AACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAA
GAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCG
GCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCT
GATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGAC
CTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACG
ACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTG
CTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAA
GTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCA
TTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTT
GTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCC
AGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGC
TTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTG
GGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTT
GGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAG
CGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGCGA
AATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTA
TCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCC
AGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAG
CATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATAC
CAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACC
GGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGT
AGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCC
GTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGA
CACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTA
GGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTA
TTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGA
TCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACG
CGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAG
TGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACC
TAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATG
GTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCC
TCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTC
GGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGC
GGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGA
GATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGC
CTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGC
AGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCC
GATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACG
AAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCT
CCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGG
GTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCT
GACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAA
ATATGTATCCGCTCAT



 Length: 3057 bp
Length: 3057 bp Restriction map B
Restriction map B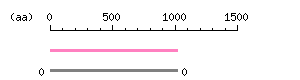

 more Linker info
more Linker info
{kind=link}