


-
SpecieshumanProduct IDFXC01984Cloning SiteSgfI-PmeISymbolADAMTSL2
Alias : ADAMTSL-2, GPHYSD1DescriptionADAMTS-like 2, transcript variant 1 Length: 2853 bp
Length: 2853 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 951 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
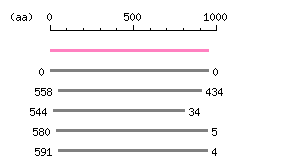
Entry Exp ID% symbol CCDS6976.1 0 99.8 ADAMTSL2 CCDS31778.2 3.6e-35 26.8 ADAMTS20 CCDS3983.2 2.8e-28 25.4 ADAMTS6 CCDS43299.1 3.8e-28 25.0 ADAMTS16 CCDS10926.1 6.7e-27 25.2 ADAMTS18
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR013273 56 74 PR01857 Peptidase M12B IPR013273 174 193 PR01857 Peptidase M12B IPR013273 194 213 PR01857 Peptidase M12B HMMPfam IPR000884 52 105 PF00090 Thrombospondin IPR010294 215 330 PF05986 ADAM-TS Spacer 1 IPR000884 627 652 PF00090 Thrombospondin IPR000884 744 794 PF00090 Thrombospondin IPR000884 802 829 PF00090 Thrombospondin IPR000884 859 907 PF00090 Thrombospondin IPR010909 915 947 PF08686 PLAC HMMSmart IPR000884 50 106 SM00209 Thrombospondin IPR000884 567 623 SM00209 Thrombospondin IPR000884 625 686 SM00209 Thrombospondin IPR000884 688 738 SM00209 Thrombospondin IPR000884 741 790 SM00209 Thrombospondin IPR000884 797 855 SM00209 Thrombospondin IPR000884 857 908 SM00209 Thrombospondin ProfileScan IPR000884 47 106 PS50092 Thrombospondin IPR000884 622 686 PS50092 Thrombospondin IPR000884 737 795 PS50092 Thrombospondin IPR000884 853 908 PS50092 Thrombospondin IPR010909 912 950 PS50900 PLAC
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 10 WAWFLLVLAVVAGDTVSTGST 30 PRIMARY 21
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_055509 951 231050,612277 99.8 100.0 NP_001138792 951 231050,612277 99.8 100.0 XP_005272296 951 231050,612277 99.8 100.0 XP_005272294 1060 231050,612277 99.8 100.0 XP_011517544 973 231050,612277 97.8 94.0 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KA0605 Download>KIAA0605 2853 bp ATGGATGGCAGATGGCAATGTTCCTGCTGGGCCTGGTTCCTGCTGGTTCTGGCAGTTGTA GCTGGGGACACAGTGTCAACCGGGTCCACGGACAACAGCCCAACATCCAATAGCCTGGAG GGGGGCACCGACGCCACGGCCTTCTGGTGGGGGGAGTGGACCAAGTGGACGGCGTTTTCC CGCAGTTGCGGGGGTGGGGTGACATCCCAGGAGCGGCACTGCCTGCAGCAGAGGAGGAAG TCCGTCCCGGGCCCCGGGAACAGGACCTGCACGGGCACGTCCAAGCGGTACCAGCTCTGC AGAGTGCAGGAGTGTCCGCCGGACGGGAGGAGCTTCCGCGAGGAGCAGTGCGTCTCCTTC AACTCCCACGTGTACAACGGGCGGACGCACCAGTGGAAGCCTCTGTACCCGGATGACTAT GTCCACATCTCCAGCAAACCGTGTGACCTGCACTGTACCACCGTGGACGGCCAGCGGCAG CTCATGGTCCCCGCCCGCGACGGCACATCCTGCAAGCTCACTGACCTGCGAGGGGTTTGC GTGTCTGGAAAATGTGAGCCCATCGGCTGTGACGGGGTGCTTTTCTCCACCCACACACTG GACAAGTGTGGCATCTGCCAGGGGGACGGTAGCAGCTGCACCCACGTGACGGGCAACTAT CGCAAGGGGAATGCCCACCTTGGTTACTCTCTGGTGACCCACATCCCGGCTGGTGCCCGA GACATCCAGATTGTAGAGAGGAAGAAGTCCGCTGACGTGCTAGCTCTTGCAGATGAAGCT GGCTACTACTTCTTCAACGGCAACTACAAGGTGGACAGCCCCAAGAACTTCAACATCGCT GGCACGGTGGTCAAGTACCGGCGGCCCATGGATGTCTATGAGACCGGAATCGAGTACATC GTGGCACAGGGGCCCACCAACCAGGGCCTGAATGTCATGGTGTGGAACCAGAACGGCAAA AGCCCCTCCATCACCTTCGAGTACACGCTGCTGCAGCCGCCACACGAGAGCCGCCCCCAG CCCATCTACTATGGCTTCTCCGAGAGCGCTGAGAGCCAGGGCCTGGACGGGGCCGGGCTG ATGGGCTTCATCCCGCACAACGGCTCCCTCTACGGCCAGGCCTCCTCAGAGCGGCTGGGC CTGGACAACCGGCTGTTCGGCCACCCGGGCCTGGACATGGAGCTGGGCCCCAGCCAGGGC CAGGAGACCAACGAGGTGTGCGAGCAGGCCGGCGGCGGGGCCTGCGAGGGGCCCCCCAGG GGCAAGGGCTTCCGAGACCGCAACGTCACGGGGACTCCTCTCACCGGGGACAAGGATGAC GAAGAGGTTGACACCCACTTCGCCTCCCAGGAGTTCTTCTCGGCTAACGCCATCTCTGAC CAGCTGCTGGGCGCAGGCTCTGACTTGAAGGACTTCACCCTCAATGAGACTGTGAACAGC ATCTTTGCACAGGGCGCCCCAAGGAGCTCCCTGGCCGAGAGCTTCTTCGTGGATTATGAG GAGAACGAGGGGGCTGGCCCTTACCTGCTCAACGGGTCCTACCTGGAGCTGAGCAGCGAC AGGGTTGCCAACAGCTCCTCCGAGGCCCCATTCCCCAACGTTAGCACCAGCCTGCTCACC TCGGCCGGGAACAGGACTCACAAGGCCAGGACCAGGCCCAAGGCGCGCAAGCAAGGCGTG AGTCCCGCGGACATGTACCGGTGGAAGCTCTCGTCCCACGAGCCCTGCAGTGCCACCTGC ACCACAGGGGTCATGTCTGCGTACGCCATGTGTGTCCGCTATGATGGCGTCGAGGTGGAT GACAGCTACTGTGACGCCCTGACCCGTCCCGAGCCTGTCCACGAGTTCTGCGCTGGGAGG GAGTGCCAGCCCAGGTGGGAGACGAGCAGCTGGAGCGAGTGTTCGCGCACCTGCGGAGAG GGCTACCAGTTCCGCGTCGTGCGCTGCTGGAAGATGCTCTCGCCCGGCTTCGACAGCTCC GTGTACAGCGACCTGTGCGAGGCAGCCGAGGCCGTGCGGCCCGAGGAACGCAAGACCTGC CGGAACCCCGCCTGCGGGCCCCAGTGGGAGATGTCGGAGTGGTCCGAGTGCACTGCCAAG TGTGGGGAGCGCAGTGTGGTGACCAGGGACATCCGCTGCTCGGAGGATGAGAAGCTGTGT GACCCCAACACCAGGCCTGTAGGGGAGAAGAACTGCACGGGCCCGCCCTGTGACCGGCAG TGGACCGTCTCCGACTGGGGACCGTGCAGTGGAAGCTGCGGGCAAGGCCGCACCATCAGG CACGTGTACTGCAAGACCAGCGACGGACGGGTAGTACCTGAGTCCCAGTGCCAGATGGAG ACCAAGCCTCTGGCCATCCACCCCTGTGGGGACAAAAACTGTCCCGCCCACTGGCTGGCC CAGGACTGGGAGCGGTGCAACACCACCTGCGGGCGCGGGGTCAAGAAGCGGCTGGTGCTC TGCATGGAGCTGGCCAACGGGAAGCCGCAGACGCGCAGTGGCCCCGAGTGCGGGCTCGCC AAGAAGCCTCCCGAGGAGAGCACGTGTTTCGAGAGGCCCTGCTTCAAGTGGTACACCAGC CCCTGGTCAGAGTGCACCAAGACCTGCGGGGTGGGCGTGAGGATGCGAGACGTCAAGTGC TACCAGGGGACCGACATCGTCCGTGGTTGCGATCCGTTGGTGAAGCCCGTTGGCAGACAG GCCTGTGATCTGCAGCCCTGCCCCACGGAGCCCCCAGATGACAGCTGCCAGGACCAGCCA GGCACCAACTGTGCCCTGGCCATCAAAGTGAACCTCTGCGGGCACTGGTACTACAGCAAG GCGTGCTGCCGCTCCTGCAGGCCCCCCCACTCC
Cloned ORF protein sequence for pF1KA0605 Download>KIAA0605 951 aa MDGRWQCSCWAWFLLVLAVVAGDTVSTGSTDNSPTSNSLEGGTDATAFWWGEWTKWTAFS RSCGGGVTSQERHCLQQRRKSVPGPGNRTCTGTSKRYQLCRVQECPPDGRSFREEQCVSF NSHVYNGRTHQWKPLYPDDYVHISSKPCDLHCTTVDGQRQLMVPARDGTSCKLTDLRGVC VSGKCEPIGCDGVLFSTHTLDKCGICQGDGSSCTHVTGNYRKGNAHLGYSLVTHIPAGAR DIQIVERKKSADVLALADEAGYYFFNGNYKVDSPKNFNIAGTVVKYRRPMDVYETGIEYI VAQGPTNQGLNVMVWNQNGKSPSITFEYTLLQPPHESRPQPIYYGFSESAESQGLDGAGL MGFIPHNGSLYGQASSERLGLDNRLFGHPGLDMELGPSQGQETNEVCEQAGGGACEGPPR GKGFRDRNVTGTPLTGDKDDEEVDTHFASQEFFSANAISDQLLGAGSDLKDFTLNETVNS IFAQGAPRSSLAESFFVDYEENEGAGPYLLNGSYLELSSDRVANSSSEAPFPNVSTSLLT SAGNRTHKARTRPKARKQGVSPADMYRWKLSSHEPCSATCTTGVMSAYAMCVRYDGVEVD DSYCDALTRPEPVHEFCAGRECQPRWETSSWSECSRTCGEGYQFRVVRCWKMLSPGFDSS VYSDLCEAAEAVRPEERKTCRNPACGPQWEMSEWSECTAKCGERSVVTRDIRCSEDEKLC DPNTRPVGEKNCTGPPCDRQWTVSDWGPCSGSCGQGRTIRHVYCKTSDGRVVPESQCQME TKPLAIHPCGDKNCPAHWLAQDWERCNTTCGRGVKKRLVLCMELANGKPQTRSGPECGLA KKPPEESTCFERPCFKWYTSPWSECTKTCGVGVRMRDVKCYQGTDIVRGCDPLVKPVGRQ ACDLQPCPTEPPDDSCQDQPGTNCALAIKVNLCGHWYYSKACCRSCRPPHS
Nucleotide Sequence (with vector) for pF1KA0605 Download>pF1KA0605 5966 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGATGGCAGA TGGCAATGTTCCTGCTGGGCCTGGTTCCTGCTGGTTCTGGCAGTTGTAGCTGGGGACACA GTGTCAACCGGGTCCACGGACAACAGCCCAACATCCAATAGCCTGGAGGGGGGCACCGAC GCCACGGCCTTCTGGTGGGGGGAGTGGACCAAGTGGACGGCGTTTTCCCGCAGTTGCGGG GGTGGGGTGACATCCCAGGAGCGGCACTGCCTGCAGCAGAGGAGGAAGTCCGTCCCGGGC CCCGGGAACAGGACCTGCACGGGCACGTCCAAGCGGTACCAGCTCTGCAGAGTGCAGGAG TGTCCGCCGGACGGGAGGAGCTTCCGCGAGGAGCAGTGCGTCTCCTTCAACTCCCACGTG TACAACGGGCGGACGCACCAGTGGAAGCCTCTGTACCCGGATGACTATGTCCACATCTCC AGCAAACCGTGTGACCTGCACTGTACCACCGTGGACGGCCAGCGGCAGCTCATGGTCCCC GCCCGCGACGGCACATCCTGCAAGCTCACTGACCTGCGAGGGGTTTGCGTGTCTGGAAAA TGTGAGCCCATCGGCTGTGACGGGGTGCTTTTCTCCACCCACACACTGGACAAGTGTGGC ATCTGCCAGGGGGACGGTAGCAGCTGCACCCACGTGACGGGCAACTATCGCAAGGGGAAT GCCCACCTTGGTTACTCTCTGGTGACCCACATCCCGGCTGGTGCCCGAGACATCCAGATT GTAGAGAGGAAGAAGTCCGCTGACGTGCTAGCTCTTGCAGATGAAGCTGGCTACTACTTC TTCAACGGCAACTACAAGGTGGACAGCCCCAAGAACTTCAACATCGCTGGCACGGTGGTC AAGTACCGGCGGCCCATGGATGTCTATGAGACCGGAATCGAGTACATCGTGGCACAGGGG CCCACCAACCAGGGCCTGAATGTCATGGTGTGGAACCAGAACGGCAAAAGCCCCTCCATC ACCTTCGAGTACACGCTGCTGCAGCCGCCACACGAGAGCCGCCCCCAGCCCATCTACTAT GGCTTCTCCGAGAGCGCTGAGAGCCAGGGCCTGGACGGGGCCGGGCTGATGGGCTTCATC CCGCACAACGGCTCCCTCTACGGCCAGGCCTCCTCAGAGCGGCTGGGCCTGGACAACCGG CTGTTCGGCCACCCGGGCCTGGACATGGAGCTGGGCCCCAGCCAGGGCCAGGAGACCAAC GAGGTGTGCGAGCAGGCCGGCGGCGGGGCCTGCGAGGGGCCCCCCAGGGGCAAGGGCTTC CGAGACCGCAACGTCACGGGGACTCCTCTCACCGGGGACAAGGATGACGAAGAGGTTGAC ACCCACTTCGCCTCCCAGGAGTTCTTCTCGGCTAACGCCATCTCTGACCAGCTGCTGGGC GCAGGCTCTGACTTGAAGGACTTCACCCTCAATGAGACTGTGAACAGCATCTTTGCACAG GGCGCCCCAAGGAGCTCCCTGGCCGAGAGCTTCTTCGTGGATTATGAGGAGAACGAGGGG GCTGGCCCTTACCTGCTCAACGGGTCCTACCTGGAGCTGAGCAGCGACAGGGTTGCCAAC AGCTCCTCCGAGGCCCCATTCCCCAACGTTAGCACCAGCCTGCTCACCTCGGCCGGGAAC AGGACTCACAAGGCCAGGACCAGGCCCAAGGCGCGCAAGCAAGGCGTGAGTCCCGCGGAC ATGTACCGGTGGAAGCTCTCGTCCCACGAGCCCTGCAGTGCCACCTGCACCACAGGGGTC ATGTCTGCGTACGCCATGTGTGTCCGCTATGATGGCGTCGAGGTGGATGACAGCTACTGT GACGCCCTGACCCGTCCCGAGCCTGTCCACGAGTTCTGCGCTGGGAGGGAGTGCCAGCCC AGGTGGGAGACGAGCAGCTGGAGCGAGTGTTCGCGCACCTGCGGAGAGGGCTACCAGTTC CGCGTCGTGCGCTGCTGGAAGATGCTCTCGCCCGGCTTCGACAGCTCCGTGTACAGCGAC CTGTGCGAGGCAGCCGAGGCCGTGCGGCCCGAGGAACGCAAGACCTGCCGGAACCCCGCC TGCGGGCCCCAGTGGGAGATGTCGGAGTGGTCCGAGTGCACTGCCAAGTGTGGGGAGCGC AGTGTGGTGACCAGGGACATCCGCTGCTCGGAGGATGAGAAGCTGTGTGACCCCAACACC AGGCCTGTAGGGGAGAAGAACTGCACGGGCCCGCCCTGTGACCGGCAGTGGACCGTCTCC GACTGGGGACCGTGCAGTGGAAGCTGCGGGCAAGGCCGCACCATCAGGCACGTGTACTGC AAGACCAGCGACGGACGGGTAGTACCTGAGTCCCAGTGCCAGATGGAGACCAAGCCTCTG GCCATCCACCCCTGTGGGGACAAAAACTGTCCCGCCCACTGGCTGGCCCAGGACTGGGAG CGGTGCAACACCACCTGCGGGCGCGGGGTCAAGAAGCGGCTGGTGCTCTGCATGGAGCTG GCCAACGGGAAGCCGCAGACGCGCAGTGGCCCCGAGTGCGGGCTCGCCAAGAAGCCTCCC GAGGAGAGCACGTGTTTCGAGAGGCCCTGCTTCAAGTGGTACACCAGCCCCTGGTCAGAG TGCACCAAGACCTGCGGGGTGGGCGTGAGGATGCGAGACGTCAAGTGCTACCAGGGGACC GACATCGTCCGTGGTTGCGATCCGTTGGTGAAGCCCGTTGGCAGACAGGCCTGTGATCTG CAGCCCTGCCCCACGGAGCCCCCAGATGACAGCTGCCAGGACCAGCCAGGCACCAACTGT GCCCTGGCCATCAAAGTGAACCTCTGCGGGCACTGGTACTACAGCAAGGCGTGCTGCCGC TCCTGCAGGCCCCCCCACTCCGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTA GAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGA GTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGT CTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAAC CGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCT TGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTT CTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTT GCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAG CCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCA AGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCAC GCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACA ATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTT GTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCG TGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGA AGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCT CCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCG GCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATG GAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCC GAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCAT GGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGAC TGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATT GCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCT CCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTC TGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGACTATAAAAGGATCTAGGTGAA GATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGC GTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAAATCCTTTTTTTCTGCGCGTAAT CTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGA GCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGT CCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATA CCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTAC CGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGG TTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCG TGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAG CGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCT TTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTC AGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTT TTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCG TATTACCGCCTTTGAGTGAGCTGATACCGGAAATACAGGAACGCACGCTGGATGGCCCTT CGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTG GCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCG GCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAAC GCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCG TAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGA TCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTT GCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACG CCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATC AAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGG TGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAAC GGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGA AGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAA ATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}