Nucleotide Sequence (with vector) for pF1KA0041
Download
>pF1KA0041 5447 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGAAGATGACT
GTGGATTTCGAGGAGTGTCTGAAGGACTCGCCCCGCTTCAGGGCAGCTTTGGAAGAAGTA
GAAGGTGATGTGGCAGAATTGGAACTAAAACTTGATAAGCTTGTGAAACTTTGTATTGCA
ATGATTGATACTGGAAAAGCCTTTTGTGTTGCAAATAAACAGTTCATGAATGGGATTCGA
GACCTGGCTCAGTATTCTAGTAATGATGCTGTCGTTGAGACAAGTTTGACCAAGTTTTCT
GACAGTCTTCAAGAAATGATAAATTTTCACACAATCCTGTTTGACCAAACTCAGAGATCA
ATTAAGGCACAGCTTCAGAACTTTGTTAAAGAAGATCTTAGAAAATTCAAAGATGCCAAG
AAGCAATTCGAAAAAGTCAGTGAAGAAAAAGAAAATGCGTTAGTAAAAAATGCCCAAGTA
CAAAGAAACAAACAACATGAAGTTGAAGAAGCCACCAACATTCTGACAGCAACAAGAAAA
TGTTTCCGACACATAGCCCTCGATTATGTGCTTCAGATTAATGTTCTTCAATCAAAAAGG
AGATCAGAAATCCTAAAATCAATGTTGTCATTTATGTATGCCCATTTGGCCTTCTTTCAT
CAAGGATATGATCTGTTTAGTGAACTTGGACCCTACATGAAGGATCTTGGTGCACAGTTG
GATCGACTGGTTGTGGATGCAGCAAAGGAGAAAAGAGAAATGGAGCAAAAACATTCCACC
ATTCAACAAAAGGATTTCTCCAGTGATGATTCTAAGTTAGAATATAACGTAGATGCTGCA
AATGGCATAGTTATGGAAGGATATCTGTTCAAACGAGCCAGCAATGCCTTCAAAACTTGG
AACAGGCGCTGGTTTTCAATACAGAATAATCAGTTGGTTTACCAGAAAAAATTTAAGGAT
AATCCGACTGTGGTAGTTGAAGACCTCAGGCTTTGCACAGTGAAACATTGTGAAGACATA
GAGCGACGATTCTGCTTTGAGGTGGTCTCGCCAACAAAAAGTTGCATGCTCCAGGCAGAT
TCCGAAAAGCTGCGCCAGGCATGGATTAAGGCTGTTCAGACCAGTATTGCTACTGCTTAT
AGAGAGAAGGGTGATGAATCAGAGAAGCTGGATAAGAAATCATCTCCATCCACAGGAAGC
CTAGATTCTGGAAATGAGTCCAAAGAGAAATTATTGAAAGGAGAAAGTGCGCTTCAGCGG
GTCCAGTGTATCCCTGGCAATGCCAGCTGTTGTGACTGTGGCCTGGCAGATCCACGGTGG
GCCAGCATCAACCTGGGCATCACCTTGTGTATCGAGTGCTCCGGAATTCACCGGAGCCTT
GGGGTTCATTTTTCAAAAGTACGATCTTTAACTTTAGACACCTGGGAGCCAGAACTTTTA
AAGCTTATGTGTGAGTTGGGGAATGATGTTATAAATCGAGTTTATGAAGCTAATGTGGAA
AAAATGGGAATAAAGAAACCCCAACCAGGACAAAGACAGGAGAAGGAGGCATATATCAGA
GCAAAATATGTGGAGAGGAAATTTGTGGATAAATATTCTATATCATTATCACCTCCTGAG
CAGCAAAAAAAGTTTGTCTCTAAAAGTTCTGAAGAAAAGAGGCTGAGCATTTCTAAATTT
GGGCCAGGGGACCAAGTCAGAGCATCTGCCCAAAGTTCAGTCAGAAGTAATGACAGTGGA
ATTCAGCAGAGCTCTGATGATGGAAGAGAATCTTTACCCTCCACGGTGTCAGCCAATAGT
TTATATGAGCCTGAAGGAGAAAGGCAAGATTCTTCTATGTTTCTTGACTCGAAACATCTT
AATCCAGGACTTCAGCTTTATAGGGCGTCATATGAAAAAAACCTTCCTAAAATGGCTGAG
GCTTTGGCTCATGGTGCAGACGTGAACTGGGCCAATTCAGAGGAAAACAAAGCGACACCA
CTTATTCAGGCTGTATTAGGGGGCTCTTTGGTGACGTGTGAGTTCCTCCTACAGAATGGT
GCTAATGTCAACCAAAGAGATGTCCAAGGGCGGGGACCATTGCACCATGCCACCGTCTTA
GGGCACACAGGGCAGGTATGTTTATTCCTAAAACGAGGTGCCAATCAACATGCCACTGAT
GAAGAAGGGAAAGACCCTTTGAGCATAGCTGTGGAAGCAGCCAATGCTGATATAGTCACC
TTGTTACGTTTAGCAAGAATGAATGAAGAGATGCGGGAATCAGAAGGACTTTATGGACAG
CCAGGTGATGAAACTTATCAGGACATATTTCGTGATTTTTCCCAAATGGCATCCAATAAT
CCAGAGAAACTAAATCGTTTCCAGCAAGATTCACAGAAATTCGTTTAAACGAATTCGAGC
TCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAA
CAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACC
CCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGG
TTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGC
TACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATT
CATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCA
GCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCG
CCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGG
ATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATG
CTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGC
TATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCG
CAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAG
GACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTC
GACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGAT
CTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGG
CGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATC
GAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAG
CATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGT
GAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGC
CGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATA
GCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTC
GTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGAC
GAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGT
ATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAA
GAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGC
GTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAG
GTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGT
GCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGG
AAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCG
CTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGG
TAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCAC
TGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTG
GCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGT
TACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGG
TGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCC
TTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTT
GGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGG
AACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGT
GGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAA
AATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCT
GCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAA
TCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGC
GTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAG
CGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCAT
GCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAG
AGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTC
GTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGG
ATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTG
CCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAA
CTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 2334 bp
Length: 2334 bp Restriction map B
Restriction map B
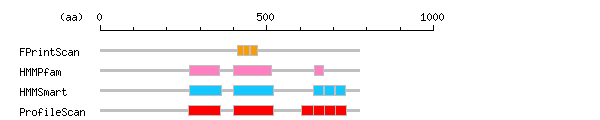
 more Linker info
more Linker info
{kind=link}