Nucleotide Sequence (with vector) for pF1KA0136
Download
>pF1KA0136 5930 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGCGGCGCAG
CCACCCCGCGGGATACGCCTCAGCGCGCTTTGCCCGAAGTTTTTACATACAAATTCTACT
AGTCACACCTGGCCATTCAGTGCAGTTGCTGAATTAATAGATAATGCTTATGATCCTGAT
GTGAACGCTAAACAAATATGGATTGACAAAACAGTGATAAATGACCATATATGCTTGACA
TTCACCGACAATGGGAATGGTATGACTTCTGATAAATTACATAAAATGCTAAGCTTTGGC
TTCAGTGACAAAGTCACCATGAATGGTCATGTCCCAGTTGGATTATATGGGAATGGCTTC
AAGTCGGGTTCTATGCGTCTGGGTAAAGACGCAATCGTTTTTACCAAAAATGGAGAAAGC
ATGAGCGTGGGCCTTTTGTCTCAGACCTACTTGGAAGTCATAAAAGCGGAGCATGTTGTT
GTTCCAATAGTGGCATTCAACAAGCACCGACAGATGATTAATTTAGCAGAATCAAAAGCC
AGCCTTGCTGCAATTCTGGAACATTCTCTGTTTTCCACGGAACAGAAGTTACTGGCAGAA
CTTGATGCTATTATAGGCAAGAAGGGGACGAGGATCATCATTTGGAATCTTAGAAGCTAC
AAAAATGCAACAGAGTTCGATTTTGAAAAGGATAAATATGATATCAGAATTCCCGAGGAT
TTAGATGAGATAACAGGGAAGAAGGGGTACAAGAAGCAGGAAAGGATGGACCAGATTGCC
CCTGAGAGTGACTATTCCCTGAGGGCTTATTGCAGTATATTATATCTAAAGCCAAGAATG
CAGATCATCCTACGTGGACAGAAAGTGAAGACACAGCTGGTTTCGAAGAGTCTTGCCTAC
ATCGAACGTGATGTTTATCGACCAAAATTTTTATCTAAAACAGTGAGAATTACCTTTGGA
TTCAACTGCAGAAATAAAGATCATTATGGGATAATGATGTATCACAGAAATAGACTCATC
AAAGCTTATGAAAAAGTTGGATGTCAGTTAAGGGCAAACAACATGGGTGTTGGAGTGGTT
GGAATTATAGAGTGTAATTTCCTTAAGCCAACTCATAATAAACAAGATTTCGACTATACT
AATGAGTACAGACTTACAATAACAGCACTAGGAGAAAAGCTGAATGATTACTGGAATGAA
ATGAAAGTGAAGAAAAATACAGAATATCCTCTAAATTTGCCAGTTGAAGATATACAGAAG
CGTCCTGATCAGACATGGGTTCAGTGTGATGCCTGTCTAAAGTGGCGGAAATTACCTGAT
GGGATGGATCAACTTCCTGAAAAATGGTATTGCTCCAATAACCCTGACCCACAGTTCAGA
AATTGTGAGGTTCCAGAAGAACCTGAAGATGAGGATTTGGTACATCCCACTTATGAAAAA
ACCTACAAAAAGACCAACAAGGAAAAATTCAGGATCAGACAACCGGAAATGATCCCTCGG
ATTAATGCTGAACTGTTGTTTCGGCCAACTGCTCTTTCAACTCCAAGCTTTTCTTCTCCT
AAGGAAAGTGTTCCAAGAAGACATCTTTCAGAAGGAACAAATTCTTATGCGACAAGACTT
CTAAATAATCATCAAGTTCCACCTCAGTCTGAACCTGAGAGCAACAGCTTGAAACGGAGA
CTTTCTACTCGTTCCTCAATTTTGAATGCAAAGAATCGGAGATTGAGTAGTCAGTTTGAA
AATTCAGTTTATAAAGGTGATGATGATGATGAAGATGTCATCATCTTAGAAGAAAACAGT
ACCCCCAAACCTGCAGTAGATCATGATATTGACATGAAATCAGAACAGAGTCACGTTGAG
CAAGGTGGTGTTCAGGTTGAGTTTGTGGGTGACAGTGAACCTTGTGGCCAGACTGGTTCA
ACAAGCACCTCATCATCCCGATGCGACCAGGGAAATACTGCAGCTACCCAGACTGAAGTA
CCAAGTTTAGTTGTTAAAAAAGAAGAAACTGTTGAAGACGAGATAGACGTAAGAAATGAT
GCAGTGATTCTGCCCTCCTGTGTAGAAGCTGAAGCAAAGATACATGAAACCCAGGAAACC
ACCGATAAATCTGCAGATGATGCAGGCTGCCAATTACAAGAACTGAGAAACCAGCTACTC
CTTGTCACTGAGGAAAAAGAGAATTATAAAAGACAGTGTCATATGTTTACTGATCAAATC
AAAGTGTTACAACAGAGGATACTAGAAATGAATGACAAGTATGTTAAGAAAGAAACTTGC
CATCAGTCCACTGAAACCGATGCTGTATTTTTACTTGAAAGTATTAATGGCAAATCTGAA
AGTCCAGACCATATGGTATCTCAGTATCAGCAAGCTTTGGAAGAAATAGAAAGGCTGAAA
AAACAATGTAGTGCTTTGCAACATGTAAAGGCTGAATGCAGCCAGTGTTCCAATAATGAG
AGTAAAAGTGAAATGGATGAGATGGCTGTGCAGCTTGACGATGTGTTTAGACAACTGGAC
AAATGCAGTATTGAGAGGGACCAGTATAAAAGTGAGGTTGAATTGCTGGAAATGGAAAAG
TCACAAATCCGTTCACAGTGTGAAGAACTCAAAACTGAAGTAGAACAGTTAAAATCTACA
AATCAACAGACGGCAACAGATGTTTCAACATCAAGTAACATTGAGGAGTCTGTAAATCAT
ATGGATGGAGAAAGCCTCAAACTCCGATCTCTTCGAGTTAACGTAGGACAACTGCTGGCT
ATGATTGTGCCTGATCTTGATCTTCAGCAAGTGAATTACGATGTTGATGTAGTTGATGAG
ATTTTAGGACAAGTTGTTGAACAAATGAGTGAAATCAGTAGTACTGTTTAAACGAATTCG
AGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGC
TAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATA
ACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATC
CGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCA
AGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGAC
ATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTA
GCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGG
GCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCA
AGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGC
ATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTC
GGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCA
GCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTG
CAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTG
CTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAG
GATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATG
CGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGC
ATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAA
GAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGAT
GGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAAT
GGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGAC
ATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTC
CTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTT
GACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACC
GGACTATAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTA
ACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTG
AAATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGC
GGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAG
CAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAA
GAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGC
CAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGC
GCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTA
CACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAG
AAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCT
TCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGA
GCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGC
GGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTT
ATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGGAAATAC
AGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTC
AGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGT
TAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTG
TCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGT
AAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGA
TGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAG
AAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCC
CATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGC
GAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCT
TTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAG
CGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAA
CTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTAC
AAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 2817 bp
Length: 2817 bp Restriction map B
Restriction map B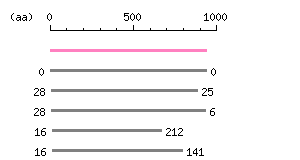

 more Linker info
more Linker info
{kind=link}