


-
SpecieshumanProduct IDFXC00186Cloning SiteSgfI-PmeISymbolKCNS2
Alias : KV9.2Descriptionpotassium voltage-gated channel, modifier subfamily S, member 2 Length: 1431 bp
Length: 1431 bp
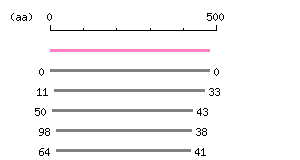
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 477 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
Entry Exp ID% symbol CCDS6279.1 1.9e-204 100.0 KCNS2 CCDS1692.1 5.3e-107 56.4 KCNS3 CCDS10945.1 2.3e-60 38.6 KCNG4 CCDS6447.1 1.8e-59 39.2 KCNV2 CCDS13436.1 1.4e-57 39.4 KCNG1
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR003971 22 34 PR01494 Potassium channel IPR003971 37 53 PR01494 Potassium channel IPR003971 60 73 PR01494 Potassium channel IPR003091 68 87 PR00169 Voltage-dependent potassium channel IPR003968 68 78 PR01491 Potassium channel IPR003971 84 99 PR01494 Potassium channel IPR003971 107 119 PR01494 Potassium channel IPR003091 180 208 PR00169 Voltage-dependent potassium channel IPR003971 193 205 PR01494 Potassium channel IPR003091 229 252 PR00169 Voltage-dependent potassium channel IPR003091 255 275 PR00169 Voltage-dependent potassium channel IPR003091 299 325 PR00169 Voltage-dependent potassium channel IPR003968 304 312 PR01491 Potassium channel IPR003091 328 351 PR00169 Voltage-dependent potassium channel IPR003968 328 342 PR01491 Potassium channel IPR003091 358 380 PR00169 Voltage-dependent potassium channel IPR003091 387 413 PR00169 Voltage-dependent potassium channel IPR003971 397 415 PR01494 Potassium channel IPR003968 398 409 PR01491 Potassium channel HMMPfam IPR003131 19 118 PF02214 Potassium channel IPR005821 229 409 PF00520 Ion transport HMMSmart IPR000210 17 126 SM00225 BTB/POZ-like
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 185 LSRVFSILSILVVMGSIITMCLN 207 PRIMARY 23 2 231 EHFGIAWFTFELVARFAVAPDFL 253 SECONDARY 23 3 261 NLIDLMSIVPFYITLVVNLVVES 283 PRIMARY 23 4 325 SYKEVGLLLLYLSVGISIFSVVA 347 SECONDARY 23 5 355 NEGLATIPACWWWATVSMTTVGY 377 SECONDARY 23 6 391 ASACILAGILVVVLPITLIFNKF 413 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_065748 477 602906 100.0 100.0 XP_011531127 491 603888 56.4 93.9 NP_002243 491 603888 56.4 93.9 NP_001269357 491 603888 56.4 93.9 XP_016859548 491 603888 56.4 93.9 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KA1144 Download>KIAA1144 1431 bp ATGACCGGCCAGAGCCTGTGGGACGTGTCGGAGGCTAACGTCGAGGACGGGGAGATCCGC ATCAATGTGGGCGGCTTCAAGAGGAGGCTGCGCTCGCACACGCTGCTGCGCTTCCCCGAG ACGCGCCTGGGCCGCTTGCTGCTCTGCCACTCGCGCGAGGCCATTCTGGAGCTCTGCGAT GACTACGACGACGTCCAGCGGGAGTTCTACTTCGACCGCAACCCTGAGCTCTTCCCCTAC GTGCTGCATTTCTATCACACCGGCAAGCTTCACGTCATGGCTGAGCTATGTGTCTTCTCC TTCAGCCAGGAGATCGAGTACTGGGGCATCAACGAGTTCTTCATTGACTCCTGCTGCAGC TACAGCTACCATGGCCGCAAAGTAGAGCCCGAGCAGGAGAAGTGGGACGAGCAGAGTGAC CAGGAGAGCACCACGTCTTCCTTCGATGAGATCCTTGCCTTCTACAACGACGCCTCCAAG TTCGATGGGCAGCCCCTCGGCAACTTCCGCAGGCAGCTGTGGCTGGCGCTGGACAACCCC GGCTACTCAGTGCTGAGCAGGGTCTTCAGCATCCTGTCCATCCTGGTGGTGATGGGGTCC ATCATCACCATGTGCCTCAATAGCCTGCCCGATTTCCAAATCCCTGACAGCCAGGGCAAC CCTGGCGAGGACCCTAGGTTCGAAATCGTGGAGCACTTTGGCATTGCCTGGTTCACATTT GAGCTGGTGGCCAGGTTTGCTGTGGCCCCTGACTTCCTCAAGTTCTTCAAGAATGCCCTA AACCTTATTGACCTCATGTCCATCGTCCCCTTTTACATCACTCTGGTGGTGAACCTGGTG GTGGAGAGCACACCTACTTTAGCCAACTTGGGCAGGGTGGCCCAGGTCCTGAGGCTGATG CGGATCTTCCGCATCTTAAAGCTGGCCAGGCACTCCACTGGCCTCCGCTCCCTGGGGGCC ACTTTGAAATACAGCTACAAAGAAGTAGGGCTGCTCTTGCTCTACCTCTCCGTGGGGATT TCCATCTTCTCCGTGGTGGCCTACACCATTGAAAAGGAGGAGAACGAGGGCCTGGCCACC ATCCCTGCCTGCTGGTGGTGGGCTACCGTCAGTATGACCACAGTGGGGTACGGGGATGTG GTCCCAGGGACCACGGCAGGAAAGCTGACTGCCTCTGCCTGCATCTTGGCAGGCATCCTC GTGGTGGTCCTGCCCATCACCTTGATCTTCAATAAGTTCTCCCACTTTTACCGGCGCCAA AAGCAACTTGAGAGTGCCATGCGCAGCTGTGACTTTGGAGATGGAATGAAGGAGGTCCCT TCGGTCAATTTAAGGGACTATTATGCCCATAAAGTTAAATCCCTTATGGCAAGCCTGACG AACATGAGCAGGAGCTCACCAAGTGAACTCAGTTTAAATGATTCCCTACGT
Cloned ORF protein sequence for pF1KA1144 Download>KIAA1144 477 aa MTGQSLWDVSEANVEDGEIRINVGGFKRRLRSHTLLRFPETRLGRLLLCHSREAILELCD DYDDVQREFYFDRNPELFPYVLHFYHTGKLHVMAELCVFSFSQEIEYWGINEFFIDSCCS YSYHGRKVEPEQEKWDEQSDQESTTSSFDEILAFYNDASKFDGQPLGNFRRQLWLALDNP GYSVLSRVFSILSILVVMGSIITMCLNSLPDFQIPDSQGNPGEDPRFEIVEHFGIAWFTF ELVARFAVAPDFLKFFKNALNLIDLMSIVPFYITLVVNLVVESTPTLANLGRVAQVLRLM RIFRILKLARHSTGLRSLGATLKYSYKEVGLLLLYLSVGISIFSVVAYTIEKEENEGLAT IPACWWWATVSMTTVGYGDVVPGTTAGKLTASACILAGILVVVLPITLIFNKFSHFYRRQ KQLESAMRSCDFGDGMKEVPSVNLRDYYAHKVKSLMASLTNMSRSSPSELSLNDSLR
Nucleotide Sequence (with vector) for pF1KA1144 Download>pF1KA1144 4544 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGACCGGCCAG AGCCTGTGGGACGTGTCGGAGGCTAACGTCGAGGACGGGGAGATCCGCATCAATGTGGGC GGCTTCAAGAGGAGGCTGCGCTCGCACACGCTGCTGCGCTTCCCCGAGACGCGCCTGGGC CGCTTGCTGCTCTGCCACTCGCGCGAGGCCATTCTGGAGCTCTGCGATGACTACGACGAC GTCCAGCGGGAGTTCTACTTCGACCGCAACCCTGAGCTCTTCCCCTACGTGCTGCATTTC TATCACACCGGCAAGCTTCACGTCATGGCTGAGCTATGTGTCTTCTCCTTCAGCCAGGAG ATCGAGTACTGGGGCATCAACGAGTTCTTCATTGACTCCTGCTGCAGCTACAGCTACCAT GGCCGCAAAGTAGAGCCCGAGCAGGAGAAGTGGGACGAGCAGAGTGACCAGGAGAGCACC ACGTCTTCCTTCGATGAGATCCTTGCCTTCTACAACGACGCCTCCAAGTTCGATGGGCAG CCCCTCGGCAACTTCCGCAGGCAGCTGTGGCTGGCGCTGGACAACCCCGGCTACTCAGTG CTGAGCAGGGTCTTCAGCATCCTGTCCATCCTGGTGGTGATGGGGTCCATCATCACCATG TGCCTCAATAGCCTGCCCGATTTCCAAATCCCTGACAGCCAGGGCAACCCTGGCGAGGAC CCTAGGTTCGAAATCGTGGAGCACTTTGGCATTGCCTGGTTCACATTTGAGCTGGTGGCC AGGTTTGCTGTGGCCCCTGACTTCCTCAAGTTCTTCAAGAATGCCCTAAACCTTATTGAC CTCATGTCCATCGTCCCCTTTTACATCACTCTGGTGGTGAACCTGGTGGTGGAGAGCACA CCTACTTTAGCCAACTTGGGCAGGGTGGCCCAGGTCCTGAGGCTGATGCGGATCTTCCGC ATCTTAAAGCTGGCCAGGCACTCCACTGGCCTCCGCTCCCTGGGGGCCACTTTGAAATAC AGCTACAAAGAAGTAGGGCTGCTCTTGCTCTACCTCTCCGTGGGGATTTCCATCTTCTCC GTGGTGGCCTACACCATTGAAAAGGAGGAGAACGAGGGCCTGGCCACCATCCCTGCCTGC TGGTGGTGGGCTACCGTCAGTATGACCACAGTGGGGTACGGGGATGTGGTCCCAGGGACC ACGGCAGGAAAGCTGACTGCCTCTGCCTGCATCTTGGCAGGCATCCTCGTGGTGGTCCTG CCCATCACCTTGATCTTCAATAAGTTCTCCCACTTTTACCGGCGCCAAAAGCAACTTGAG AGTGCCATGCGCAGCTGTGACTTTGGAGATGGAATGAAGGAGGTCCCTTCGGTCAATTTA AGGGACTATTATGCCCATAAAGTTAAATCCCTTATGGCAAGCCTGACGAACATGAGCAGG AGCTCACCAAGTGAACTCAGTTTAAATGATTCCCTACGTGTTTAAACGAATTCGAGCTCG GTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAA AGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCT TGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTC GCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTAC CTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCAT CCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCC CTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCC TCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATC TGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTT GAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTAT GACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAG GGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGAC GAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGAC GTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTC CTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGG CTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAG CGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCAT CAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAG GATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGC TTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCG TTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTG CTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAG TTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATC AGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAA CATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTT TTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTG GCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCG CTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAG CGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTC CAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAA CTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGG TAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCC TAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTAC CTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGG TTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTT GATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGT CATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAAC GCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGA TTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAAT TTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCT GCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCC ACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTC CGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGG TCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCC GAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGT AGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTT TTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATT TGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCA GGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTC TTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}