Nucleotide Sequence (with vector) for pF1KSDA0915
Download
>pF1KSDA0915 5662 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGTCAGCCCAGTCCCTTCCTGCAGCAACACCCCCCACGCAGAAGCCCCCTCGG
ATCATCCGCCCCCGCCCTCCTTCTCGTTCCAGGGCTGCCCAGTCCCCAGGGCCTCCCCAC
AATGGCTCCTCTCCACAAGAACTACCCCGAAACTCCAATGATGCACCAACCCCAATGTGC
ACCCCCATCTTCTGGGAGCCCCCAGCTGCATCCCTCAAGCCCCCTGCTCTTTTGCCCCCC
TCAGCTTCTAGAGCCAGCCTCGACTCCCAGACTTCCCCAGACTCACCTTCCAGCACCCCC
ACACCTAGTCCAGTGTCCCGGCGCTCCGCCTCCCCAGAACCTGCTCCCCGGTCTCCAGTC
CCCCCACCCAAGCCGTCTGGGTCACCCTGCACGCCTCTGCTCCCCATGGCTGGAGTCCTG
GCTCAGAATGGCTCTGCCTCAGCTCCTGGCACTGTGCGGAGGCTGGCTGGCAGGTTTGAA
GGGGGTGCTGAAGGCCGGGCTCAGGATGCAGATGCCCCGGAGCCAGGTCTCCAAGCGAGA
GCAGATGTGAATGGGGAGAGAGAAGCTCCCCTCACCGGGAGTGGGTCCCAGGAGAACGGT
GCTCCAGATGCTGGCCTGGCCTGCCCTCCCTGCTGCCCCTGTGTCTGCCACACCACCCGG
CCTGGCCTGGAGCTCAGATGGGTGCCTGTGGGGGGCTATGAGGAGGTCCCCAGGGTCCCC
CGTCGGGCCTCCCCGCTGCGGACCTCTCGCTCCCGCCCCCACCCTCCAAGCATCGGTCAC
CCTGCCGTTGTCCTCACATCCTACCGCTCCACTGCTGAGCGCAAACTCCTGCCACTCCTC
AAGCCTCCCAAACCAACTCGTGTCAGGCAGGATGCCACCATTTTCGGGGACCCCCCACAG
CCAGATCTTGATCTGCTTTCTGAAGATGGAATCCAAACAGGGGACAGTCCTGATGAAGCT
CCTCAGAATACTCCTCCAGCAACTGTGGAGGGGAGGGAAGAGGAGGGGCTAGAGGTGCTG
AAGGAGCAGAATTGGGAGCTGCCCCTGCAGGATGAACCTCTGTACCAGACCTACCGAGCA
GCCGTGCTGTCAGAGGAGCTGTGGGGGGTGGGTGAGGATGGGAGTCCTTCTCCAGCAAAT
GCTGGAGATGCACCCACCTTCCCACGACCCCCTGGACCTCGCAACACCCTGTGGCAGGAG
CTTCCGGCTGTGCAAGCCAGCGGTCTTCTGGATACCCTCAGCCCCCAGGAGAGGCGCATG
CAGGAGAGTCTTTTCGAGGTGGTGACGTCCGAGGCTTCCTACCTGCGCTCCCTGCGGCTG
CTGACCGACACCTTCGTGCTGAGCCAGGCACTCCGGGACACGCTCACCCCCCGTGATCAC
CACACACTCTTCTCCAATGTGCAGCGAGTCCAGGGAGTCAGCGAGCGGTTTCTAGCAACG
CTCCTGTCCCGTGTGCGCTCTTCCCCCCACATCAGCGACTTGTGTGATGTGGTGCATGCC
CACGCTGTGGGGCCTTTCTCGGTGTATGTGGATTATGTGCGGAACCAGCAGTATCAGGAG
GAGACCTACAGCCGCCTCATGGACACCAACGTGCGCTTCTCCGCCGAGCTGCGCCGGCTG
CAGAGCCTCCCTAAGTGTGAGCGGCTCCCGCTGCCGTCCTTCCTGCTACTGCCCTTCCAG
CGCATCACCCGGCTGCGCATGCTGCTGCAGAATATCCTGCGCCAGACAGAAGAGGGGTCC
AGCCGTCAGGAGAATGCCCAGAAGGCCCTGGGTGCTGTCAGCAAGATCATCGAGCGTTGC
AGCGCTGAGGTGGGGCGCATGAAGCAGACTGAAGAGCTGATCCGGCTCACCCAAAGGCTG
CGCTTCCACAAAGTCAAGGCCCTGCCCCTGGTCTCCTGGTCACGGCGCCTGGAATTCCAG
GGAGAGCTGACTGAGTTAGGGTGCCGGAGGGGGGGCGTGCTCTTTGCCTCGCGCCCCCGC
TTCACCCCTCTTTGCCTGCTGCTCTTTAGCGACCTGCTGCTCATCACTCAGCCTAAGAGT
GGGCAGCGGTTACAGGTTCTGGACTATGCCCATCGCTCCCTGGTCCAGGCCCAGCAGGTT
CCGGATCCATCTGGACCCCCTACCTTCCGCCTCTCCCTTCTCAGCAACCACCAGGGCCGC
CCCACCCACCGACTACTCCAAGCTTCTTCCCTATCAGACATGCAGCGCTGGCTGGGAGCC
TTCCCAACCCCAGGCCCCCTTCCCTGCTCCCCAGACACCATCTATGAGGACTGTGACTGT
TCCCAGGAACTGTGTTCAGAGTCGTCTGCACCTGCCAAGACTGAAGGACGGAGTCTGGAG
TCCAGGGCTGCCCCCAAACACCTGCACAAGACCCCTGAAGGTTGGCTGAAGGGGCTTCCT
GGGGCCTTCCCTGCCCAGCTGGTGTGTGAAGTCACAGGGGAACACGAAAGGAGGAGGCAC
CTTCGCCAGAACCAGAGGCTTCTCGAGGCTGTTGGACCTTCTTCAGGCACCCCCAATGCC
CCCCCACCCTACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCG
ACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGC
TGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAG
GGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCA
GTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTT
TTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGG
ACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCA
GCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGC
AAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCT
GATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGT
TCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGC
TGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAG
ACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTG
GCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGAC
TGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCC
GAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACC
TGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCC
GGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTG
TTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGAT
GCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGC
CGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAA
GAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGAT
TCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGT
TCGCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATA
CGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAA
AAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCT
GACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAA
AGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCG
CTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCA
CGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAA
CCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCG
GTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGG
TATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGG
ACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGC
TCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAG
ATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGAC
GCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATC
TTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCT
GGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCT
GTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAG
TTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGT
TTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGC
CATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTT
TTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCT
GGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGT
AGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAAT
AAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAA
CGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCC
CGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGC
CATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATAC
ATTCAAATATGTATCCGCTCAT



 Length: 2523 bp
Length: 2523 bp Restriction map B
Restriction map B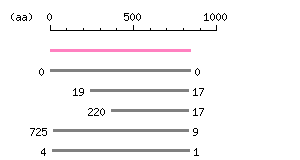

 more Linker info
more Linker info
{kind=link}