


-
SpecieshumanProduct IDFXC00779Cloning SiteSgfI-PmeISymbolLRFN2
Alias : FIGLER2, KIAA1246, SALM1Descriptionleucine rich repeat and fibronectin type III domain containing 2 Length: 2367 bp
Length: 2367 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 789 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
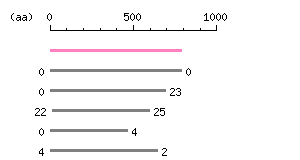
Entry Exp ID% symbol CCDS34443.1 1.4e-177 100.0 LRFN2 CCDS9678.1 5.5e-77 51.7 LRFN5 CCDS12483.1 3.6e-66 53.5 LRFN3 CCDS81800.1 7.5e-59 57.6 LRFN5 CCDS8153.1 9.3e-52 53.5 LRFN4
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR001611 198 215 PF00560 Leucine-rich repeat IPR013098 290 376 PF07679 Immunoglobulin I-set IPR003961 420 494 PF00041 Fibronectin HMMSmart IPR003591 75 98 SM00369 Leucine-rich repeat IPR003591 99 122 SM00369 Leucine-rich repeat IPR003591 123 146 SM00369 Leucine-rich repeat IPR003591 148 171 SM00369 Leucine-rich repeat IPR003591 172 195 SM00369 Leucine-rich repeat IPR003591 196 220 SM00369 Leucine-rich repeat IPR000483 242 287 SM00082 Cysteine-rich flanking region IPR003599 295 377 SM00409 Immunoglobulin subtype IPR003598 301 366 SM00408 Immunoglobulin subtype 2 ProfileScan IPR001611 77 98 PS51450 Leucine-rich repeat IPR001611 101 122 PS51450 Leucine-rich repeat IPR001611 125 146 PS51450 Leucine-rich repeat IPR001611 150 171 PS51450 Leucine-rich repeat IPR001611 174 195 PS51450 Leucine-rich repeat IPR001611 198 219 PS51450 Leucine-rich repeat IPR007110 289 375 PS50835 Immunoglobulin-like IPR003961 418 510 PS50853 Fibronectin
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 1 METLLGGLLAFGMAFAVVDACPK 23 PRIMARY 23 2 531 GGTMILVIGGIIVATLLVFIVIL 553 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) XP_016866599 789 612808 100.0 100.0 XP_011513063 789 612808 100.0 100.0 XP_011513064 789 612808 100.0 100.0 NP_065788 789 612808 100.0 100.0 NP_001333102 719 612811 51.7 87.6 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA1246 Download>KIAA1246 2367 bp ATGGAGACCCTGCTTGGTGGCCTGCTAGCGTTTGGCATGGCGTTTGCCGTGGTCGACGCC TGCCCCAAGTACTGTGTCTGCCAGAATCTGTCTGAGTCACTGGGGACCCTGTGCCCCTCC AAGGGGCTGCTCTTTGTACCCCCTGATATTGACCGGCGGACAGTGGAGCTGCGCCTGGGC GGCAACTTCATCATCCACATCAGCCGCCAGGACTTTGCCAACATGACGGGGCTGGTGGAC CTGACCCTGTCCAGGAACACCATCAGCCACATCCAGCCCTTTTCCTTTCTGGACCTCGAG AGCCTCCGCTCCCTGCATCTTGACAGCAATCGGCTGCCAAGCCTTGGGGAGGACACCCTC CGGGGCCTGGTCAACCTGCAGCACCTTATCGTGAACAACAACCAGCTGGGCGGCATCGCA GATGAGGCTTTTGAGGACTTCCTGCTGACATTGGAGGATCTGGACCTCTCCTACAACAAC CTCCATGGCCTGCCGTGGGACTCCGTGCGACGCATGGTCAACCTCCACCAGCTGAGCCTG GACCACAACCTGCTGGATCACATCGCCGAGGGCACCTTTGCAGACCTGCAGAAACTGGCC CGCCTGGATCTCACCTCCAATCGGCTGCAGAAGCTGCCCCCTGATCCCATCTTTGCCCGC TCCCAGGCTTCGGCTTTGACAGCCACACCCTTTGCCCCACCCTTGTCCTTTAGTTTTGGG GGTAACCCACTTCACTGCAATTGTGAGCTTCTCTGGCTGCGGAGGCTCGAGCGGGACGAT GACCTGGAAACCTGTGGCTCCCCAGGGGGCCTCAAGGGTCGCTACTTCTGGCATGTGCGT GAGGAGGAGTTTGTGTGCGAGCCGCCTCTCATCACCCAGCACACACACAAGTTGCTGGTT CTGGAGGGCCAGGCGGCCACACTCAAGTGCAAAGCCATTGGGGACCCCAGCCCCCTTATC CACTGGGTAGCCCCCGATGACCGCCTGGTAGGGAACTCCTCAAGGACCGCTGTCTATGAC AATGGCACCCTGGACATCTTCATCACCACATCTCAGGACAGTGGTGCCTTCACCTGCATT GCTGCCAATGCTGCCGGAGAGGCCACGGCCATGGTGGAGGTCTCCATCGTCCAGCTGCCA CACCTCAGCAACAGCACCAGCCGCACTGCACCCCCCAAGTCCCGCCTCTCAGACATCACT GGCTCCAGCAAGACCAGCCGGGGAGGTGGAGGCAGTGGGGGCGGAGAGCCTCCCAAAAGC CCCCCGGAACGGGCTGTGCTTGTGTCTGAAGTGACCACCACCTCGGCCCTGGTCAAGTGG TCTGTCAGCAAGTCAGCACCCCGGGTGAAGATGTACCAGCTGCAGTACAACTGCTCTGAC GATGAGGTACTGATTTACAGGATGATCCCAGCCTCCAACAAGGCCTTCGTGGTCAACAAC CTGGTGTCAGGGACTGGCTACGACTTGTGTGTGCTGGCCATGTGGGATGACACAGCCACG ACACTCACGGCCACCAACATCGTGGGCTGCGCCCAGTTCTTCACCAAGGCTGACTACCCG CAGTGCCAGTCCATGCACAGCCAGATTCTGGGCGGCACCATGATCCTGGTCATCGGGGGC ATCATCGTGGCCACGCTGCTGGTCTTCATCGTCATCCTCATGGTGCGCTACAAGGTCTGC AACCACGAGGCCCCCAGCAAGATGGCAGCGGCCGTGAGCAATGTGTACTCGCAGACCAAC GGCGCCCAGCCACCGCCTCCAAGCAGCGCACCAGCCGGGGCCCCGCCGCAGGGCCCGCCG AAGGTGGTGGTGCGCAACGAGCTCCTGGACTTCACCGCCAGCCTGGCCCGCGCCAGTGAC TCCTCTTCCTCCAGCTCCCTGGGCAGTGGGGAGGCTGCGGGGCTGGGACGGGCCCCCTGG AGGATCCCACCCTCCGCCCCGCGCCCCAAGCCCAGCCTTGACCGCCTGATGGGGGCCTTC GCCTCCCTGGACCTCAAGAGTCAGAGAAAGGAGGAGCTGCTGGACTCCAGGACTCCAGCC GGGAGAGGGGCTGGGACGTCGGCCCGGGGCCACCACTCGGACCGAGAGCCACTGCTGGGG CCCCCTGCGGCCCGGGCCAGGAGCCTGCTCCCCTTGCCGTTGGAGGGCAAGGCCAAACGC AGCCACTCCTTCGACATGGGGGACTTTGCTGCTGCGGCGGCGGGAGGGGTCGTGCCGGGC GGCTACAGTCCTCCTCGGAAGGTCTCGAACATCTGGACGAAGCGCAGCCTCTCTGTCAAC GGCATGCTCTTGCCCTTTGAGGAGAGTGACCTGGTGGGGGCCCGGGGGACTTTTGGCAGC TCCGAATGGGTGATGGAGAGCACGGTC
Cloned ORF protein sequence for pF1KSDA1246 Download>KIAA1246 789 aa METLLGGLLAFGMAFAVVDACPKYCVCQNLSESLGTLCPSKGLLFVPPDIDRRTVELRLG GNFIIHISRQDFANMTGLVDLTLSRNTISHIQPFSFLDLESLRSLHLDSNRLPSLGEDTL RGLVNLQHLIVNNNQLGGIADEAFEDFLLTLEDLDLSYNNLHGLPWDSVRRMVNLHQLSL DHNLLDHIAEGTFADLQKLARLDLTSNRLQKLPPDPIFARSQASALTATPFAPPLSFSFG GNPLHCNCELLWLRRLERDDDLETCGSPGGLKGRYFWHVREEEFVCEPPLITQHTHKLLV LEGQAATLKCKAIGDPSPLIHWVAPDDRLVGNSSRTAVYDNGTLDIFITTSQDSGAFTCI AANAAGEATAMVEVSIVQLPHLSNSTSRTAPPKSRLSDITGSSKTSRGGGGSGGGEPPKS PPERAVLVSEVTTTSALVKWSVSKSAPRVKMYQLQYNCSDDEVLIYRMIPASNKAFVVNN LVSGTGYDLCVLAMWDDTATTLTATNIVGCAQFFTKADYPQCQSMHSQILGGTMILVIGG IIVATLLVFIVILMVRYKVCNHEAPSKMAAAVSNVYSQTNGAQPPPPSSAPAGAPPQGPP KVVVRNELLDFTASLARASDSSSSSSLGSGEAAGLGRAPWRIPPSAPRPKPSLDRLMGAF ASLDLKSQRKEELLDSRTPAGRGAGTSARGHHSDREPLLGPPAARARSLLPLPLEGKAKR SHSFDMGDFAAAAAGGVVPGGYSPPRKVSNIWTKRSLSVNGMLLPFEESDLVGARGTFGS SEWVMESTV
Nucleotide Sequence (with vector) for pF1KSDA1246 Download>pF1KSDA1246 5506 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGGAGACCCTGCTTGGTGGCCTGCTAGCGTTTGGCATGGCGTTTGCCGTGGTC GACGCCTGCCCCAAGTACTGTGTCTGCCAGAATCTGTCTGAGTCACTGGGGACCCTGTGC CCCTCCAAGGGGCTGCTCTTTGTACCCCCTGATATTGACCGGCGGACAGTGGAGCTGCGC CTGGGCGGCAACTTCATCATCCACATCAGCCGCCAGGACTTTGCCAACATGACGGGGCTG GTGGACCTGACCCTGTCCAGGAACACCATCAGCCACATCCAGCCCTTTTCCTTTCTGGAC CTCGAGAGCCTCCGCTCCCTGCATCTTGACAGCAATCGGCTGCCAAGCCTTGGGGAGGAC ACCCTCCGGGGCCTGGTCAACCTGCAGCACCTTATCGTGAACAACAACCAGCTGGGCGGC ATCGCAGATGAGGCTTTTGAGGACTTCCTGCTGACATTGGAGGATCTGGACCTCTCCTAC AACAACCTCCATGGCCTGCCGTGGGACTCCGTGCGACGCATGGTCAACCTCCACCAGCTG AGCCTGGACCACAACCTGCTGGATCACATCGCCGAGGGCACCTTTGCAGACCTGCAGAAA CTGGCCCGCCTGGATCTCACCTCCAATCGGCTGCAGAAGCTGCCCCCTGATCCCATCTTT GCCCGCTCCCAGGCTTCGGCTTTGACAGCCACACCCTTTGCCCCACCCTTGTCCTTTAGT TTTGGGGGTAACCCACTTCACTGCAATTGTGAGCTTCTCTGGCTGCGGAGGCTCGAGCGG GACGATGACCTGGAAACCTGTGGCTCCCCAGGGGGCCTCAAGGGTCGCTACTTCTGGCAT GTGCGTGAGGAGGAGTTTGTGTGCGAGCCGCCTCTCATCACCCAGCACACACACAAGTTG CTGGTTCTGGAGGGCCAGGCGGCCACACTCAAGTGCAAAGCCATTGGGGACCCCAGCCCC CTTATCCACTGGGTAGCCCCCGATGACCGCCTGGTAGGGAACTCCTCAAGGACCGCTGTC TATGACAATGGCACCCTGGACATCTTCATCACCACATCTCAGGACAGTGGTGCCTTCACC TGCATTGCTGCCAATGCTGCCGGAGAGGCCACGGCCATGGTGGAGGTCTCCATCGTCCAG CTGCCACACCTCAGCAACAGCACCAGCCGCACTGCACCCCCCAAGTCCCGCCTCTCAGAC ATCACTGGCTCCAGCAAGACCAGCCGGGGAGGTGGAGGCAGTGGGGGCGGAGAGCCTCCC AAAAGCCCCCCGGAACGGGCTGTGCTTGTGTCTGAAGTGACCACCACCTCGGCCCTGGTC AAGTGGTCTGTCAGCAAGTCAGCACCCCGGGTGAAGATGTACCAGCTGCAGTACAACTGC TCTGACGATGAGGTACTGATTTACAGGATGATCCCAGCCTCCAACAAGGCCTTCGTGGTC AACAACCTGGTGTCAGGGACTGGCTACGACTTGTGTGTGCTGGCCATGTGGGATGACACA GCCACGACACTCACGGCCACCAACATCGTGGGCTGCGCCCAGTTCTTCACCAAGGCTGAC TACCCGCAGTGCCAGTCCATGCACAGCCAGATTCTGGGCGGCACCATGATCCTGGTCATC GGGGGCATCATCGTGGCCACGCTGCTGGTCTTCATCGTCATCCTCATGGTGCGCTACAAG GTCTGCAACCACGAGGCCCCCAGCAAGATGGCAGCGGCCGTGAGCAATGTGTACTCGCAG ACCAACGGCGCCCAGCCACCGCCTCCAAGCAGCGCACCAGCCGGGGCCCCGCCGCAGGGC CCGCCGAAGGTGGTGGTGCGCAACGAGCTCCTGGACTTCACCGCCAGCCTGGCCCGCGCC AGTGACTCCTCTTCCTCCAGCTCCCTGGGCAGTGGGGAGGCTGCGGGGCTGGGACGGGCC CCCTGGAGGATCCCACCCTCCGCCCCGCGCCCCAAGCCCAGCCTTGACCGCCTGATGGGG GCCTTCGCCTCCCTGGACCTCAAGAGTCAGAGAAAGGAGGAGCTGCTGGACTCCAGGACT CCAGCCGGGAGAGGGGCTGGGACGTCGGCCCGGGGCCACCACTCGGACCGAGAGCCACTG CTGGGGCCCCCTGCGGCCCGGGCCAGGAGCCTGCTCCCCTTGCCGTTGGAGGGCAAGGCC AAACGCAGCCACTCCTTCGACATGGGGGACTTTGCTGCTGCGGCGGCGGGAGGGGTCGTG CCGGGCGGCTACAGTCCTCCTCGGAAGGTCTCGAACATCTGGACGAAGCGCAGCCTCTCT GTCAACGGCATGCTCTTGCCCTTTGAGGAGAGTGACCTGGTGGGGGCCCGGGGGACTTTT GGCAGCTCCGAATGGGTGATGGAGAGCACGGTCTACGTAGTTTAAACGAATTCGAGCTCG GTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAA AGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCT TGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTC GCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTAC CTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCAT CCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCC CTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCC TCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATC TGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTT GAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTAT GACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAG GGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGAC GAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGAC GTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTC CTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGG CTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAG CGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCAT CAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAG GATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGC TTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCG TTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTG CTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAG TTCTTCTGAGCGGGACTCTGGGGTTCGCGAAATGACCGACCAAGCGACGCCCAACCGGTA TCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAG AACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCG TTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGG TGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTG CGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGA AGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGC TCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGT AACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACT GGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGG CCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTT ACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGT GGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCT TTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTG GTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGA ACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTG GATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAA ATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTG CTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAAT CCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCG TCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGC GGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATG CCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGA GTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCG TTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGA TTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGC CAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAAC TCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}