


-
SpecieshumanProduct IDFXC00834Cloning SiteSgfI-PmeISymbolLRRC8A
Alias : AGM5, HsLRRC8A, LRRC8, SWELL1Descriptionleucine rich repeat containing 8 family, member A, transcript variant 2 Length: 2430 bp
Length: 2430 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 810 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS35155.1 0 100.0 LRRC8A CCDS724.1 8.2e-174 59.0 LRRC8B CCDS725.1 1.8e-173 57.8 LRRC8C CCDS726.1 1.8e-154 55.0 LRRC8D CCDS12189.1 2e-142 53.5 LRRC8E
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]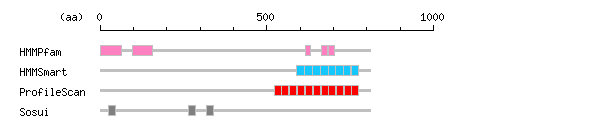 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR021040 1 63 PF12534 Leucine-rich repeat-containing protein 8 IPR021040 98 156 PF12534 Leucine-rich repeat-containing protein 8 IPR001611 615 632 PF00560 Leucine-rich repeat IPR001611 663 682 PF00560 Leucine-rich repeat IPR001611 686 704 PF00560 Leucine-rich repeat HMMSmart IPR003591 590 613 SM00369 Leucine-rich repeat NULL 613 634 SM00365 NULL IPR003591 614 636 SM00369 Leucine-rich repeat IPR003591 638 660 SM00369 Leucine-rich repeat NULL 661 692 SM00365 NULL IPR003591 661 684 SM00369 Leucine-rich repeat IPR003591 685 706 SM00369 Leucine-rich repeat IPR003591 707 730 SM00369 Leucine-rich repeat IPR003591 731 751 SM00369 Leucine-rich repeat NULL 753 773 SM00365 NULL IPR003591 753 776 SM00369 Leucine-rich repeat ProfileScan IPR001611 522 544 PS51450 Leucine-rich repeat IPR001611 545 565 PS51450 Leucine-rich repeat IPR001611 568 588 PS51450 Leucine-rich repeat IPR001611 592 613 PS51450 Leucine-rich repeat IPR001611 615 636 PS51450 Leucine-rich repeat IPR001611 640 662 PS51450 Leucine-rich repeat IPR001611 663 684 PS51450 Leucine-rich repeat IPR001611 686 707 PS51450 Leucine-rich repeat IPR001611 709 730 PS51450 Leucine-rich repeat IPR001611 732 753 PS51450 Leucine-rich repeat IPR001611 755 776 PS51450 Leucine-rich repeat
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 25 DVFTDYISIVMLMIAVFGGTLQV 47 SECONDARY 23 2 265 MRQTIIKVIKFILIICYTVYYVH 287 PRIMARY 23 3 318 FKILASFYISLVIFYGLICMYTL 340 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001120716 810 608360,613506 100.0 100.0 XP_006717249 810 608360,613506 100.0 100.0 NP_062540 810 608360,613506 100.0 100.0 XP_005252152 810 608360,613506 100.0 100.0 NP_001120717 810 608360,613506 100.0 100.0 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA1437 Download>KIAA1437 2430 bp ATGATTCCGGTGACAGAGCTCCGCTACTTTGCGGACACGCAGCCAGCATACCGGATCCTG AAGCCGTGGTGGGATGTGTTCACAGACTACATCTCTATCGTCATGCTGATGATTGCCGTC TTCGGGGGGACGCTGCAGGTCACCCAAGACAAGATGATCTGCCTGCCTTGTAAGTGGGTC ACCAAGGACTCCTGCAATGATTCGTTCCGGGGCTGGGCAGCCCCTGGCCCGGAGCCCACC TACCCCAACTCCACCATTCTGCCGACCCCTGACACGGGCCCCACAGGCATCAAGTATGAC CTGGACCGGCACCAGTACAACTACGTGGACGCTGTGTGCTATGAGAACCGACTGCACTGG TTTGCCAAGTACTTCCCCTACCTGGTGCTTCTGCACACGCTCATCTTCCTGGCCTGCAGC AACTTCTGGTTCAAATTCCCGCGCACCAGCTCGAAGCTGGAGCACTTTGTGTCTATCCTG CTGAAGTGCTTCGACTCGCCCTGGACCACGAGGGCCCTGTCGGAGACAGTGGTGGAGGAG AGCGACCCCAAGCCGGCCTTCAGCAAGATGAATGGGTCCATGGACAAAAAGTCATCGACC GTCAGTGAGGACGTGGAGGCCACCGTGCCCATGCTGCAGCGGACCAAGTCACGGATCGAG CAGGGTATCGTGGACCGCTCAGAGACGGGCGTGCTGGACAAGAAGGAGGGGGAGCAAGCC AAGGCGCTGTTTGAGAAGGTGAAGAAGTTCCGGACCCATGTGGAGGAGGGGGACATTGTG TACCGCCTCTACATGCGGCAGACCATCATCAAGGTGATCAAGTTCATCCTCATCATCTGC TACACCGTCTACTACGTGCACAACATCAAGTTCGACGTGGACTGCACCGTGGACATTGAG AGCCTGACGGGCTACCGCACCTACCGCTGTGCCCACCCCCTGGCCACACTCTTCAAGATC CTGGCGTCCTTCTACATCAGCCTAGTCATCTTCTACGGCCTCATCTGCATGTATACACTG TGGTGGATGCTACGGCGCTCCCTCAAGAAGTACTCGTTTGAGTCGATCCGTGAGGAGAGC AGCTACAGCGACATCCCCGACGTCAAGAACGACTTCGCCTTCATGCTGCACCTCATTGAC CAATACGACCCGCTCTACTCCAAGCGCTTCGCCGTCTTCCTGTCGGAGGTGAGTGAGAAC AAGCTGCGGCAGCTGAACCTCAACAACGAGTGGACGCTGGACAAGCTCCGGCAGCGGCTC ACCAAGAACGCGCAGGACAAGCTGGAGCTGCACCTGTTCATGCTCAGTGGCATCCCTGAC ACTGTGTTTGACCTGGTGGAGCTGGAGGTCCTCAAGCTGGAGCTGATCCCCGACGTGACC ATCCCGCCCAGCATTGCCCAGCTCACGGGCCTCAAGGAGCTGTGGCTCTACCACACAGCG GCCAAGATTGAAGCGCCCGCGCTGGCCTTCCTGCGCGAGAACCTGCGGGCGCTGCACATC AAGTTCACCGACATCAAGGAGATCCCGCTGTGGATCTATAGCCTGAAGACACTGGAGGAG CTGCACCTGACGGGCAACCTGAGCGCGGAGAACAACCGCTACATCGTCATCGACGGGCTG CGGGAGCTCAAACGCCTCAAGGTGCTGCGGCTCAAGAGCAACCTAAGCAAGCTGCCACAG GTGGTCACAGATGTGGGCGTGCACCTGCAGAAGCTGTCCATCAACAATGAGGGCACCAAG CTCATCGTCCTCAACAGCCTCAAGAAGATGGCGAACCTGACTGAGCTGGAGCTGATCCGC TGTGACCTGGAGCGCATCCCCCACTCCATCTTCAGCCTCCACAACCTGCAGGAGATTGAC CTCAAGGACAACAACCTCAAGACCATCGAGGAGATCATCAGCTTCCAGCACCTGCACCGC CTCACCTGCCTTAAGCTGTGGTACAACCACATCGCCTACATCCCCATCCAGATCGGCAAC CTCACCAACCTGGAGCGCCTCTACCTGAACCGCAACAAGATCGAGAAGATCCCCACCCAG CTCTTCTACTGCCGCAAGCTGCGCTACCTGGACCTCAGCCACAACAACCTGACCTTCCTC CCTGCCGACATCGGCCTCCTGCAGAACCTCCAGAACCTAGCCATCACGGCCAACCGGATC GAGACGCTCCCTCCGGAGCTCTTCCAGTGCCGGAAGCTGCGGGCCCTGCACCTGGGCAAC AACGTGCTGCAGTCACTGCCCTCCAGGGTGGGCGAGCTGACCAACCTGACGCAGATCGAG CTGCGGGGCAACCGGCTGGAGTGCCTGCCTGTGGAGCTGGGCGAGTGCCCACTGCTCAAG CGCAGCGGCTTGGTGGTGGAGGAGGACCTGTTCAACACACTGCCACCCGAGGTGAAGGAG CGGCTGTGGAGGGCTGACAAGGAGCAGGCC
Cloned ORF protein sequence for pF1KSDA1437 Download>KIAA1437 810 aa MIPVTELRYFADTQPAYRILKPWWDVFTDYISIVMLMIAVFGGTLQVTQDKMICLPCKWV TKDSCNDSFRGWAAPGPEPTYPNSTILPTPDTGPTGIKYDLDRHQYNYVDAVCYENRLHW FAKYFPYLVLLHTLIFLACSNFWFKFPRTSSKLEHFVSILLKCFDSPWTTRALSETVVEE SDPKPAFSKMNGSMDKKSSTVSEDVEATVPMLQRTKSRIEQGIVDRSETGVLDKKEGEQA KALFEKVKKFRTHVEEGDIVYRLYMRQTIIKVIKFILIICYTVYYVHNIKFDVDCTVDIE SLTGYRTYRCAHPLATLFKILASFYISLVIFYGLICMYTLWWMLRRSLKKYSFESIREES SYSDIPDVKNDFAFMLHLIDQYDPLYSKRFAVFLSEVSENKLRQLNLNNEWTLDKLRQRL TKNAQDKLELHLFMLSGIPDTVFDLVELEVLKLELIPDVTIPPSIAQLTGLKELWLYHTA AKIEAPALAFLRENLRALHIKFTDIKEIPLWIYSLKTLEELHLTGNLSAENNRYIVIDGL RELKRLKVLRLKSNLSKLPQVVTDVGVHLQKLSINNEGTKLIVLNSLKKMANLTELELIR CDLERIPHSIFSLHNLQEIDLKDNNLKTIEEIISFQHLHRLTCLKLWYNHIAYIPIQIGN LTNLERLYLNRNKIEKIPTQLFYCRKLRYLDLSHNNLTFLPADIGLLQNLQNLAITANRI ETLPPELFQCRKLRALHLGNNVLQSLPSRVGELTNLTQIELRGNRLECLPVELGECPLLK RSGLVVEEDLFNTLPPEVKERLWRADKEQA
Nucleotide Sequence (with vector) for pF1KSDA1437 Download>pF1KSDA1437 5567 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGATTCCGGTGACAGAGCTCCGCTACTTTGCGGACACGCAGCCAGCATACCGG ATCCTGAAGCCGTGGTGGGATGTGTTCACAGACTACATCTCTATCGTCATGCTGATGATT GCCGTCTTCGGGGGGACGCTGCAGGTCACCCAAGACAAGATGATCTGCCTGCCTTGTAAG TGGGTCACCAAGGACTCCTGCAATGATTCGTTCCGGGGCTGGGCAGCCCCTGGCCCGGAG CCCACCTACCCCAACTCCACCATTCTGCCGACCCCTGACACGGGCCCCACAGGCATCAAG TATGACCTGGACCGGCACCAGTACAACTACGTGGACGCTGTGTGCTATGAGAACCGACTG CACTGGTTTGCCAAGTACTTCCCCTACCTGGTGCTTCTGCACACGCTCATCTTCCTGGCC TGCAGCAACTTCTGGTTCAAATTCCCGCGCACCAGCTCGAAGCTGGAGCACTTTGTGTCT ATCCTGCTGAAGTGCTTCGACTCGCCCTGGACCACGAGGGCCCTGTCGGAGACAGTGGTG GAGGAGAGCGACCCCAAGCCGGCCTTCAGCAAGATGAATGGGTCCATGGACAAAAAGTCA TCGACCGTCAGTGAGGACGTGGAGGCCACCGTGCCCATGCTGCAGCGGACCAAGTCACGG ATCGAGCAGGGTATCGTGGACCGCTCAGAGACGGGCGTGCTGGACAAGAAGGAGGGGGAG CAAGCCAAGGCGCTGTTTGAGAAGGTGAAGAAGTTCCGGACCCATGTGGAGGAGGGGGAC ATTGTGTACCGCCTCTACATGCGGCAGACCATCATCAAGGTGATCAAGTTCATCCTCATC ATCTGCTACACCGTCTACTACGTGCACAACATCAAGTTCGACGTGGACTGCACCGTGGAC ATTGAGAGCCTGACGGGCTACCGCACCTACCGCTGTGCCCACCCCCTGGCCACACTCTTC AAGATCCTGGCGTCCTTCTACATCAGCCTAGTCATCTTCTACGGCCTCATCTGCATGTAT ACACTGTGGTGGATGCTACGGCGCTCCCTCAAGAAGTACTCGTTTGAGTCGATCCGTGAG GAGAGCAGCTACAGCGACATCCCCGACGTCAAGAACGACTTCGCCTTCATGCTGCACCTC ATTGACCAATACGACCCGCTCTACTCCAAGCGCTTCGCCGTCTTCCTGTCGGAGGTGAGT GAGAACAAGCTGCGGCAGCTGAACCTCAACAACGAGTGGACGCTGGACAAGCTCCGGCAG CGGCTCACCAAGAACGCGCAGGACAAGCTGGAGCTGCACCTGTTCATGCTCAGTGGCATC CCTGACACTGTGTTTGACCTGGTGGAGCTGGAGGTCCTCAAGCTGGAGCTGATCCCCGAC GTGACCATCCCGCCCAGCATTGCCCAGCTCACGGGCCTCAAGGAGCTGTGGCTCTACCAC ACAGCGGCCAAGATTGAAGCGCCCGCGCTGGCCTTCCTGCGCGAGAACCTGCGGGCGCTG CACATCAAGTTCACCGACATCAAGGAGATCCCGCTGTGGATCTATAGCCTGAAGACACTG GAGGAGCTGCACCTGACGGGCAACCTGAGCGCGGAGAACAACCGCTACATCGTCATCGAC GGGCTGCGGGAGCTCAAACGCCTCAAGGTGCTGCGGCTCAAGAGCAACCTAAGCAAGCTG CCACAGGTGGTCACAGATGTGGGCGTGCACCTGCAGAAGCTGTCCATCAACAATGAGGGC ACCAAGCTCATCGTCCTCAACAGCCTCAAGAAGATGGCGAACCTGACTGAGCTGGAGCTG ATCCGCTGTGACCTGGAGCGCATCCCCCACTCCATCTTCAGCCTCCACAACCTGCAGGAG ATTGACCTCAAGGACAACAACCTCAAGACCATCGAGGAGATCATCAGCTTCCAGCACCTG CACCGCCTCACCTGCCTTAAGCTGTGGTACAACCACATCGCCTACATCCCCATCCAGATC GGCAACCTCACCAACCTGGAGCGCCTCTACCTGAACCGCAACAAGATCGAGAAGATCCCC ACCCAGCTCTTCTACTGCCGCAAGCTGCGCTACCTGGACCTCAGCCACAACAACCTGACC TTCCTCCCTGCCGACATCGGCCTCCTGCAGAACCTCCAGAACCTAGCCATCACGGCCAAC CGGATCGAGACGCTCCCTCCGGAGCTCTTCCAGTGCCGGAAGCTGCGGGCCCTGCACCTG GGCAACAACGTGCTGCAGTCACTGCCCTCCAGGGTGGGCGAGCTGACCAACCTGACGCAG ATCGAGCTGCGGGGCAACCGGCTGGAGTGCCTGCCTGTGGAGCTGGGCGAGTGCCCACTG CTCAAGCGCAGCGGCTTGGTGGTGGAGGAGGACCTGTTCAACACACTGCCACCCGAGGTG AAGGAGCGGCTGTGGAGGGCTGACAAGGAGCAGGCCTACGTAGTTTAAACGAATTCGAGC TCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAA CAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACC CCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGG TTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGC TACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATT CATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCA GCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCG CCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGG ATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATG CTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGC TATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCG CAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAG GACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTC GACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGAT CTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGG CGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATC GAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAG CATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGT GAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGC CGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATA GCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTC GTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGAC GAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGT ATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAA GAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGC GTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAG GTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGT GCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGG AAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCG CTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGG TAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCAC TGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTG GCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGT TACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGG TGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCC TTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTT GGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGG AACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGT GGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAA AATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCT GCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAA TCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGC GTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAG CGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCAT GCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAG AGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTC GTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGG ATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTG CCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAA CTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}