Nucleotide Sequence (with vector) for pF1KSDA0093
Download
>pF1KSDA0093 5839 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGCAACTTGCGCGGTGGAGGTGTTCGGGCTCCTGGAGGACGAGGAAAATTCA
CGAATTGTGAGAGTAAGAGTTATAGCCGGAATAGGCCTTGCCAAGAAGGATATATTGGGA
GCTAGTGATCCTTACGTGAGAGTGACGTTATATGACCCAATGAATGGAGTTCTTACAAGT
GTGCAAACAAAAACCATTAAAAAGAGTTTGAATCCAAAGTGGAATGAAGAAATATTATTC
AGAGTTCATCCTCAGCAGCACCGGCTTCTTTTTGAAGTGTTTGACGAAAACCGATTGACA
AGAGATGATTTCCTAGGTCAAGTGGATGTTCCACTTTATCCATTACCGACAGAAAATCCA
AGATTGGAGAGACCATATACATTTAAGGATTTTGTTCTTCATCCAAGAAGTCACAAATCA
AGAGTTAAAGGTTATCTGAGACTAAAAATGACTTATTTACCTAAAACCAGTGGCTCAGAA
GATGATAATGCAGAACAGGCTGAGGAATTAGAGCCTGGCTGGGTTGTTTTGGACCAACCA
GATGCTGCTTGCCATTTGCAGCAACAACAAGAACCTTCTCCTCTACCTCCAGGGTGGGAA
GAGAGGCAGGATATCCTTGGAAGGACCTATTATGTAAACCATGAATCTAGAAGAACACAG
TGGAAAAGACCAACCCCTCAGGACAACCTAACAGATGCTGAGAATGGCAACATTCAACTG
CAAGCACAACGTGCATTTACCACCAGGCGGCAGATATCCGAGGAAACAGAAAGTGTTGAC
AACCAAGAGTCTTCCGAGAACTGGGAAATTATAAGAGAAGATGAAGCCACCATGTATAGC
AGCCAGGCCTTCCCATCACCTCCACCGTCAAGTAACTTGGATGTTCCAACTCATCTTGCA
GAAGAATTGAATGCCAGACTCACCATTTTTGGAAATTCAGCCGTGAGCCAGCCAGCATCG
AGCTCAAATCATTCCAGCAGAAGAGGCAGCTTACAAGCCTATACTTTTGAGGAACAACCT
ACACTTCCTGTGCTTTTGCCTACTTCATCTGGATTACCACCAGGTTGGGAAGAAAAACAA
GATGAAAGAGGAAGATCATATTATGTAGATCACAATTCCAGAACGACTACTTGGACAAAG
CCCACTGTACAGGCCACAGTGGAGACCAGTCAGCTGACCTCAAGCCAGAGTTCTGCAGGC
CCTCAATCACAAGCCTCCACCAGTGATTCAGGCCAGCAGGTGACCCAGCCATCTGAAATT
GAGCAAGGATTCCTTCCTAAAGGCTGGGAAGTCCGGCATGCACCAAATGGGAGGCCTTTC
TTTATTGACCACAACACTAAAACCACCACCTGGGAAGATCCAAGATTGAAAATTCCAGCC
CATCTGAGAGGAAAGACATCACTTGATACTTCCAATGATCTAGGGCCTTTACCTCCAGGA
TGGGAAGAGAGAACTCACACAGATGGAAGAATCTTCTACATAAATCACAATATAAAAAGA
ACACAATGGGAAGATCCTCGGTTGGAGAATGTAGCAATAACTGGACCAGCAGTGCCCTAC
TCCAGGGATTACAAAAGAAAGTATGAGTTCTTCCGAAGAAAGTTGAAGAAGCAGAATGAC
ATTCCAAACAAATTTGAAATGAAACTTCGCCGAGCAACTGTTCTTGAAGACTCTTACCGG
AGAATTATGGGTGTCAAGAGAGCAGACTTCCTGAAGGCTCGACTGTGGATTGAGTTTGAT
GGTGAAAAGGGATTGGATTATGGAGGAGTTGCCAGAGAATGGTTCTTCCTGATCTCAAAG
GAAATGTTTAACCCTTATTATGGGTTGTTTGAATATTCTGCTACGGACAATTATACCCTA
CAGATAAATCCAAACTCTGGATTGTGTAACGAAGATCACCTCTCTTACTTCAAGTTTATT
GGTCGGGTAGCTGGAATGGCAGTTTATCATGGCAAACTGTTGGATGGTTTTTTCATCCGC
CCATTTTACAAGATGATGCTTCACAAACCAATAACCCTTCATGATATGGAATCTGTGGAT
AGTGAATATTACAATTCCCTAAGATGGATTCTTGAAAATGACCCAACAGAATTGGACCTC
AGGTTTATCATAGATGAAGAACTTTTTGGACAGACACATCAACATGAGCTGAAAAATGGT
GGATCAGAAATAGTTGTCACCAATAAGAACAAAAAGGAATATATTTATCTTGTAATACAA
TGGCGATTTGTAAACCGAATCCAGAAGCAAATGGCTGCTTTTAAAGAGGGATTCTTTGAA
CTAATACCACAGGATCTCATCAAAATTTTTGATGAAAATGAACTAGAGCTTCTTATGTGT
GGACTGGGAGATGTTGATGTGAATGACTGGAGGGAACATACAAAGTATAAAAATGGCTAC
AGTGCAAATCATCAGGTTATACAGTGGTTTTGGAAGGCTGTTTTAATGATGGATTCAGAA
AAAAGAATAAGATTACTTCAGTTTGTCACTGGCACATCTCGGGTGCCTATGAATGGATTT
GCTGAACTATACGGTTCAAATGGACCACAGTCATTTACAGTTGAACAGTGGGGTACGCCT
GAAAAGCTGCCAAGAGCTCATACCTGTTTTAATCGCCTGGACTTGCCACCTTATGAATCA
TTTGAAGAATTATGGGATAAACTTCAGATGGCAATTGAAAACACCCAGGGCTTTGATGGA
GTTGATTACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACC
TGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGC
TGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGG
TTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTC
TAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTC
CCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACT
GGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCG
TGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAA
GTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGAT
CAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCT
CCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGC
TCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACC
GACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCC
ACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGG
CTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAG
AAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGC
CCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGT
CTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTC
GCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCC
TGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGG
CTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAG
CTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCG
CAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCG
CGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGG
TTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAG
GCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGAC
GAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGA
TACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTT
ACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGC
TGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCC
CCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTA
AGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTAT
GTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACA
GTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCT
TGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATT
ACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCT
CAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTC
ACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGG
ATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTA
CCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTT
TTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTT
AGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCAT
CGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTC
AGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGC
GGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGC
GCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAA
ACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGC
TCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGG
AGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCAT
CCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATT
CAAATATGTATCCGCTCAT



 Length: 2700 bp
Length: 2700 bp Restriction map B
Restriction map B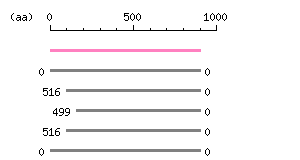

 more Linker info
more Linker info
{kind=link}