Nucleotide Sequence (with vector) for pF1KSDA0157
Download
>pF1KSDA0157 4382 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGCGGCGTCCATTTCGGGCTACACCTTCAGTGCTGTGTGTTTCCACAGCGCC
AACAGCAACGCGGACCACGAAGGATTTTTACTGGGAGAGGTAAGACAAGAGGAAACGTTT
AGCATCAGTGACTCACAAATCAGCAACACAGAATTTCTGCAAGTAATTCAAATCTATAAC
CATCAGCCTTGTTCAAAACTTTTTAGTTTTTATGACTACGCAAGCAAAGTGAATGAGGAG
AGTTTGGACAGGATTCTTAAAGATCGGAGAAAGAAAGTCATTGGGTGGTACAGATTCCGG
CGCAATACGCAGCAGCAGATGTCCTACAGAGAGCAGGTTCTTCACAAGCAGCTCACCCGC
ATCCTCGGCGTGCCCGACCTCGTCTTTCTTCTCTTCAGCTTCATCTCCACTGCCAACAAT
TCCACTCACGCTTTAGAATATGTGCTCTTCAGACCAAATAGAAGGTATAATCAGAGGATA
TCACTCGCTATTCCCAATCTAGGAAATACTAGCCAGCAAGAGTACAAAGTGTCTTCAGTG
CCAAATACTTCTCAGAGTTATGCCAAAGTGATTAAAGAACATGGTACTGACTTTTTTGAC
AAGGATGGAGTAATGAAAGACATCAGGGCGATTTATCAGGTTTATAATGCACTTCAGGAG
AAAGTTCAGGCAGTGTGTGCAGATGTTGAAAAGAGTGAGCGAGTTGTTGAATCTTGTCAG
GCAGAAGTGAACAAATTAAGAAGACAAATCACTCAGAGGAAAAATGAAAAGGAACAAGAA
AGAAGATTGCAGCAGGCAGTGTTAAGCAGACAGATGCCGTCTGAAAGCTTGGACCCAGCG
TTCAGTCCTCGGATGCCGTCCTCTGGGTTTGCAGCTGAAGGCAGAAGTACACTTGGAGAT
GCAGAGGCCTCGGATCCTCCTCCCCCTTACTCTGATTTTCACCCAAACAATCAAGAAAGT
ACTTTGAGCCACTCTCGCATGGAAAGGAGTGTCTTTATGCCTCGACCTCAAGCTGTGGGC
TCTTCCAATTATGCTTCCACCAGTGCCGGACTGAAGTATCCTGGAAGTGGGGCTGACCTT
CCTCCTCCCCAAAGAGCAGCTGGAGACAGTGGTGAGGATTCAGACGACAGTGATTATGAA
AATTTGATTGACCCTACAGAGCCTTCTAATAGTGAATACTCACATTCAAAGGATTCTCGA
CCCATGGCACATCCCGACGAGGACCCCAGGAACACTCAGACCTCCCAGATTTACGTAGTT
TAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGC
TGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCA
ATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGG
AGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGT
AAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGC
CCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTT
CCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAA
TTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCT
TTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGA
CGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTG
GAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTG
TTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCC
CTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCT
TGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAA
GTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATG
GCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAA
GCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGAT
GATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCG
CGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATC
ATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGAC
CGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGG
GCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTC
TATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAG
CGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGG
GGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAA
GGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCG
ACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCC
TGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGC
CTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTC
GGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCG
CTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCC
ACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGA
GTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGC
TCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAAC
CACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGG
ATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTC
ACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATA
GTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAA
AATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGG
TATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGC
CATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTA
AGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTA
CTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAA
ATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGT
CCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGG
GTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGA
AAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAA
ATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGAC
GCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTT
TTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTC
AT



 Length: 1245 bp
Length: 1245 bp Restriction map B
Restriction map B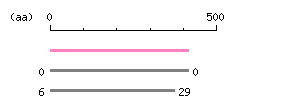

 more Linker info
more Linker info
{kind=link}