Nucleotide Sequence (with vector) for pF1KA0519
Download
>pF1KA0519 5870 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGACAGGCTAT
ACCATGCTGCGGAATGGGGGCGCGGGGAACGGAGGTCAGACCTGCATGCTGCGCTGGTCC
AACCGCATCCGCCTCACGTGGCTCAGCTTCACGCTCTTTGTCATCCTGGTCTTCTTCCCG
CTCATCGCCCACTATTACCTCACCACTCTGGATGAGGCTGATGAGGCAGGCAAGCGGATT
TTTGGTCCCCGGGTGGGGAACGAGCTGTGCGAGGTGAAGCACGTGCTGGATCTGTGCCGC
ATCCGGGAGTCGGTGAGTGAAGAGCTCCTGCAGCTGGAGGCCAAGCGCCAAGAGCTGAAC
AGCGAGATCGCCAAGCTGAATCTGAAGATCGAAGCCTGTAAGAAGAGCATTGAGAACGCC
AAGCAGGACCTGCTCCAGCTCAAGAATGTCATCAGCCAGACCGAGCATTCCTACAAGGAG
CTCATGGCCCAGAACCAGCCCAAGCTGTCCCTGCCCATCCGACTGCTCCCAGAGAAGGAC
GATGCCGGCCTCCCTCCCCCGAAGGCCACTCGGGGCTGCCGGCTACACAACTGCTTTGAT
TATTCTCGTTGCCCTCTCACCTCTGGCTTCCCGGTCTACGTCTATGACAGTGACCAGTTT
GTCTTTGGCAGCTACCTGGATCCCTTGGTCAAGCAGGCTTTTCAGGCGACAGCACGAGCT
AACGTTTATGTTACAGAAAATGCAGACATCGCCTGCCTTTACGTGATACTAGTGGGAGAG
ATGCAGGAGCCGGTGGTGCTGCGGCCTGCTGAGCTGGAGAAGCAGTTGTATTCCCTGCCA
CACTGGCGGACGGATGGACACAACCATGTCATCATCAATCTGTCACGTAAGTCAGATACA
CAGAACCTTCTCTATAACGTCAGTACTGGCCGTGCCATGGTGGCCCAGTCCACCTTCTAC
ACTGTCCAGTACAGACCTGGCTTTGACTTGGTCGTATCACCGCTGGTCCATGCCATGTCT
GAGCCCAACTTCATGGAAATCCCACCACAGGTGCCGGTGAAGCGGAAATATCTCTTCACC
TTCCAGGGCGAGAAGATTGAGTCTCTGAGGTCTAGCCTTCAGGAGGCCCGCTCCTTCGAA
GAGGAAATGGAGGGCGACCCTCCCGCCGACTACGATGACCGGATCATTGCCACCCTGAAG
GCGGTGCAGGACAGCAAGCTGGATCAGGTCCTGGTGGAATTCACCTGCAAAAACCAGCCC
AAACCCAGCCTGCCGACTGAGTGGGCACTGTGTGGAGAGCGGGAGGACCGCTTGGAATTG
CTGAAGCTCTCCACCTTCGCCCTCATCATTACCCCCGGGGACCCTCGCTTGGTTATTTCC
TCTGGGTGTGCAACACGGCTCTTCGAAGCCCTGGAAGTCGGTGCCGTCCCGGTGGTGCTG
GGGGAGCAGGTCCAGCTTCCCTACCAGGACATGCTGCAGTGGAACGAGGCGGCCCTGGTG
GTGCCAAAGCCTCGTGTTACCGAGGTTCATTTCCTGCTCAGAAGCCTCTCCGATAGTGAC
CTCCTGGCTATGAGGCGGCAAGGCCGCTTTCTCTGGGAGACTTACTTCTCCACTGCTGAC
AGTATTTTTAATACCGTGCTGGCTATGATTAGGACTCGCATCCAGATCCCAGCCGCTCCC
ATCCGGGAAGAGGCGGCAGCTGAGATCCCCCACCGTTCAGGCAAGGCGGCTGGAACTGAC
CCCAACATGGCTGACAACGGGGACCTGGACCTGGGGCCAGTGGAGACGGAGCCGCCCTAC
GCCTCACCCAGATACCTCCGCAATTTCACTCTGACTGTCACTGACTTTTACCGCAGCTGG
AACTGTGCTCCAGGGCCTTTCCATCTTTTCCCCCACACTCCCTTTGACCCTGTGTTGCCC
TCAGAGGCCAAATTCTTGGGCTCAGGGACTGGCTTTCGGCCTATTGGTGGTGGAGCTGGG
GGTTCTGGCAAGGAATTTCAGGCAGCGCTTGGAGGCAATGTTCCCCGAGAGCAGTTCACG
GTGGTGATGTTGACTTATGAGCGGGAGGAAGTGCTTATGAACTCTTTAGAGAGGCTGAAT
GGCCTCCCTTACCTGAACAAGGTCGTGGTGGTGTGGAATTCTCCCAAGCTGCCATCAGAG
GACCTTCTGTGGCCTGACATTGGCGTCCCCATCATGGTGGTCCGTACTGAGAAGAACAGT
TTGAACAACCGATTCTTACCCTGGAATGAAATTGAGACAGAGGCCATCCTGTCCATTGAT
GACGATGCTCACCTCCGCCATGACGAAATCATGTTTGGGTTCCGGGTGTGGAGAGAAGCT
CGGGACCGCATCGTGGGCTTCCCTGGCCGTTACCACGCATGGGACATCCCCCATCAGTCC
TGGCTCTACAACTCCAACTACTCCTGTGAGCTGTCCATGGTGCTGACAGGTGCTGCCTTC
TTTCACAAGTATTATGCCTACCTGTATTCTTATGTGATGCCCCAGGCCATCCGGGACATG
GTGGATGAATACATCAACTGTGAGGACATTGCCATGAACTTCCTTGTCTCCCACATCACT
CGGAAGCCCCCCATCAAGGTGACCTCACGGTGGACATTCCGATGCCCAGGATGCCCTCAG
GCCCTGTCTCATGATGACTCCCACTTCCACGAGCGGCACAAGTGCATCAACTTCTTCGTG
AAGGTGTACGGCTACATGCCCCTCCTGTACACGCAGTTCAGGGTGGATTCTGTGCTCTTC
AAGACACGCCTGCCCCATGACAAGACCAAGTGCTTCAAGTTCATCGTTTAAACGAATTCG
AGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGC
TAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATA
ACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATC
CGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCA
AGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGAC
ATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTA
GCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGG
GCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCA
AGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGC
ATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTC
GGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCA
GCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTG
CAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTG
CTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAG
GATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATG
CGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGC
ATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAA
GAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGAT
GGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAAT
GGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGAC
ATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTC
CTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTT
GACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACC
GGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGG
AAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCT
GGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCA
GAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCT
CGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTC
GGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGT
TCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATC
CGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGC
CACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTG
GTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCC
AGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAG
CGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGA
TCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGAT
TTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATAC
AGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTC
AGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGT
TAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTG
TCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGT
AAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGA
TGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAG
AAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCC
CATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGC
GAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCT
TTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAG
CGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAA
CTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTAC
AAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 2757 bp
Length: 2757 bp Restriction map B
Restriction map B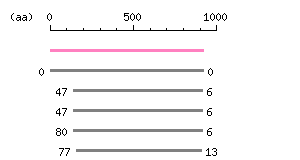

 more Linker info
more Linker info
{kind=link}