


-
SpecieshumanProduct IDFXC00587Cloning SiteSgfI-PmeISymbolTRILDescriptionTLR4 interactor with leucine-rich repeats
 Length: 2433 bp
Length: 2433 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 811 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS75573.1 3.7e-197 99.9 TRIL CCDS47218.1 5.1e-16 31.3 LRRC70 CCDS10446.1 1.5e-13 34.8 IGFALS CCDS53982.1 1.6e-13 34.8 IGFALS CCDS13777.1 5.8e-12 33.4 RTN4R
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]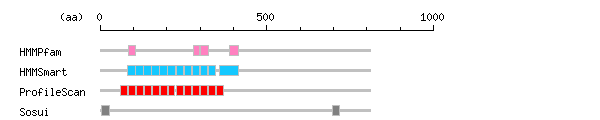 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR001611 84 106 PF00560 Leucine-rich repeat IPR001611 279 297 PF00560 Leucine-rich repeat IPR001611 302 324 PF00560 Leucine-rich repeat IPR000483 387 415 PF01463 Cysteine-rich flanking region HMMSmart IPR003591 82 105 SM00369 Leucine-rich repeat IPR003591 106 129 SM00369 Leucine-rich repeat IPR003591 130 153 SM00369 Leucine-rich repeat IPR003591 154 177 SM00369 Leucine-rich repeat IPR003591 178 201 SM00369 Leucine-rich repeat IPR003591 202 227 SM00369 Leucine-rich repeat IPR003591 228 251 SM00369 Leucine-rich repeat IPR003591 252 275 SM00369 Leucine-rich repeat IPR003591 276 299 SM00369 Leucine-rich repeat IPR003591 300 323 SM00369 Leucine-rich repeat IPR003591 324 347 SM00369 Leucine-rich repeat IPR000483 359 415 SM00082 Cysteine-rich flanking region ProfileScan IPR001611 61 81 PS51450 Leucine-rich repeat IPR001611 84 105 PS51450 Leucine-rich repeat IPR001611 108 129 PS51450 Leucine-rich repeat IPR001611 132 153 PS51450 Leucine-rich repeat IPR001611 156 177 PS51450 Leucine-rich repeat IPR001611 180 201 PS51450 Leucine-rich repeat IPR001611 204 223 PS51450 Leucine-rich repeat IPR001611 230 251 PS51450 Leucine-rich repeat IPR001611 254 275 PS51450 Leucine-rich repeat IPR001611 278 299 PS51450 Leucine-rich repeat IPR001611 302 323 PS51450 Leucine-rich repeat IPR001611 326 347 PS51450 Leucine-rich repeat IPR001611 350 371 PS51450 Leucine-rich repeat
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 5 RALRLLLVVCGCLALPPLAEPVC 27 PRIMARY 23 2 696 QLLTLALLTVNALLVLLALAAWA 718 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA0644 Download>KIAA0644 2433 bp ATGGAGGCTGCCCGCGCCTTGCGCCTCCTGCTCGTGGTGTGCGGCTGCCTCGCGCTCCCG CCGCTGGCCGAGCCCGTGTGCCCGGAGCGCTGCGACTGCCAGCATCCCCAGCATCTCCTG TGCACCAACAGGGGGCTCCGCGTAGTGCCCAAGACCAGCTCGCTGCCGAGCCCCCACGAC GTGCTCACCTACAGCCTCGGCGGCAACTTCATAACCAACATCACGGCCTTCGACTTCCAC CGTCTGGGGCAGCTCAGACGGCTGGACCTGCAGTACAACCAGATCCGCTCTCTGCACCCC AAGACCTTCGAGAAGCTCTCGCGGCTGGAAGAGCTGTACCTGGGGAACAACCTCTTGCAG GCGCTCGCCCCGGGCACGCTGGCCCCGCTGCGCAAGCTGCGCATCCTCTACGCCAACGGG AACGAGATCAGCCGCCTAAGCCGCGGCTCCTTCGAGGGCCTGGAGAGTCTAGTCAAGCTG CGGCTGGACGGGAACGCCCTGGGGGCGCTGCCGGACGCGGTCTTCGCTCCCTTGGGCAAC CTGCTCTACCTACATCTGGAGTCCAACCGGATCCGCTTTCTGGGCAAGAACGCCTTCGCC CAGCTAGGCAAGCTGCGCTTCCTCAACCTCTCTGCCAACGAGCTACAGCCCTCCCTGCGC CACGCGGCCACCTTCGCACCGCTGCGCTCCCTCTCCTCCCTCATCCTCTCGGCCAACAGC CTGCAGCACCTCGGGCCGCGCATCTTCCAGCACCTGCCACGTCTCGGCCTGCTCTCGCTC AGGGGCAACCAGCTCACGCACCTCGCGCCTGAGGCCTTTTGGGGCTTGGAGGCCCTGCGC GAGCTGCGCCTGGAGGGTAATCGGCTGAGCCAGCTGCCAACTGCGCTGCTGGAGCCTCTG CACAGCCTGGAGGCGCTGGACCTGAGCGGCAATGAGCTGTCCGCCCTGCACCCGGCCACC TTCGGCCACCTGGGCCGGCTGCGCGAGCTCAGCCTGCGCAACAACGCGCTCAGCGCCCTA TCCGGGGACATCTTCGCCGCCAGCCCAGCCCTTTATCGGCTGGATCTAGACGGCAACGGC TGGACCTGCGACTGCCGGCTGCGAGGCCTGAAGCGCTGGATGGGCGACTGGCACTCGCAG GGCCGGCTCCTCACTGTCTTCGTGCAGTGTCGCCACCCCCCGGCCCTGCGAGGCAAATAC CTGGATTACCTGGATGACCAGCAGCTGCAAAATGGATCCTGCGCGGATCCCTCGCCCTCA GCTTCCCTGACCGCTGACCGCAGGCGGCAGCCCCTACCCACGGCCGCAGGGGAGGAGATG ACGCCACCTGCAGGTCTCGCGGAGGAGCTGCCGCCGCAGCCGCAGCTCCAGCAGCAGGGG CGATTTCTAGCTGGGGTGGCCTGGGATGGGGCCGCCAGGGAGCTGGTAGGCAACCGCAGC GCTCTAAGGCTGAGTCGGCGGGGCCCGGGCCTCCAGCAGCCCAGCCCCTCCGTCGCTGCC GCCGCGGGCCCGGCTCCACAGTCCCTAGACCTGCACAAGAAGCCCCAGCGGGGCCGTCCG ACTCGGGCAGATCCCGCCCTCGCGGAGCCCACCCCAACGGCCTCTCCTGGCTCTGCGCCA TCGCCCGCCGGCGACCCCTGGCAGCGCGCGACGAAGCATCGTCTGGGCACGGAGCACCAG GAGCGTGCCGCCCAGTCCGACGGTGGGGCCGGGCTGCCGCCGCTGGTGTCCGACCCATGC GACTTCAACAAGTTCATTCTGTGCAACCTGACGGTGGAGGCGGTGGGCGCAGACAGCGCC TCGGTGCGCTGGGCCGTGCGCGAGCACCGCAGTCCCCGGCCGCTGGGCGGCGCGCGCTTC CGCCTGCTCTTTGACCGCTTTGGCCAGCAGCCCAAGTTCCACCGCTTCGTCTACCTGCCT GAGAGCAGCGACTCGGCCACGCTGCGCGAGCTGCGCGGGGACACCCCCTACCTGGTGTGC GTGGAGGGCGTGCTTGGGGGCCGTGTCTGCCCTGTGGCTCCCCGGGACCACTGCGCGGGG CTGGTCACCCTACCGGAGGCCGGGAGCCGGGGCGGCGTCGACTACCAGCTGCTGACCTTG GCCCTGCTGACGGTCAACGCGCTGCTGGTGCTCCTGGCCTTGGCGGCCTGGGCGTCTCGC TGGCTGCGTAGGAAACTGCGGGCTAGGCGGAAGGGCGGGGCCCCGGTCCACGTTCGGCAC ATGTACTCCACCCGACGGCCCCTGCGCTCCATGGGCACCGGCGTGTCCGCCGACTTCTCG GGATTCCAGTCGCACCGGCCACGCACCACCGTGTGCGCGCTCAGTGAGGCGGACCTCATC GAATTCCCCTGCGACCGCTTCATGGACAGTGCGGGCGGCGGCGCGGGCGGCAGCCTGAGA CGGGAGGACCGTCTCCTGCAGCGATTTGCCGAC
Cloned ORF protein sequence for pF1KSDA0644 Download>KIAA0644 811 aa MEAARALRLLLVVCGCLALPPLAEPVCPERCDCQHPQHLLCTNRGLRVVPKTSSLPSPHD VLTYSLGGNFITNITAFDFHRLGQLRRLDLQYNQIRSLHPKTFEKLSRLEELYLGNNLLQ ALAPGTLAPLRKLRILYANGNEISRLSRGSFEGLESLVKLRLDGNALGALPDAVFAPLGN LLYLHLESNRIRFLGKNAFAQLGKLRFLNLSANELQPSLRHAATFAPLRSLSSLILSANS LQHLGPRIFQHLPRLGLLSLRGNQLTHLAPEAFWGLEALRELRLEGNRLSQLPTALLEPL HSLEALDLSGNELSALHPATFGHLGRLRELSLRNNALSALSGDIFAASPALYRLDLDGNG WTCDCRLRGLKRWMGDWHSQGRLLTVFVQCRHPPALRGKYLDYLDDQQLQNGSCADPSPS ASLTADRRRQPLPTAAGEEMTPPAGLAEELPPQPQLQQQGRFLAGVAWDGAARELVGNRS ALRLSRRGPGLQQPSPSVAAAAGPAPQSLDLHKKPQRGRPTRADPALAEPTPTASPGSAP SPAGDPWQRATKHRLGTEHQERAAQSDGGAGLPPLVSDPCDFNKFILCNLTVEAVGADSA SVRWAVREHRSPRPLGGARFRLLFDRFGQQPKFHRFVYLPESSDSATLRELRGDTPYLVC VEGVLGGRVCPVAPRDHCAGLVTLPEAGSRGGVDYQLLTLALLTVNALLVLLALAAWASR WLRRKLRARRKGGAPVHVRHMYSTRRPLRSMGTGVSADFSGFQSHRPRTTVCALSEADLI EFPCDRFMDSAGGGAGGSLRREDRLLQRFAD
Nucleotide Sequence (with vector) for pF1KSDA0644 Download>pF1KSDA0644 5572 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGGAGGCTGCCCGCGCCTTGCGCCTCCTGCTCGTGGTGTGCGGCTGCCTCGCG CTCCCGCCGCTGGCCGAGCCCGTGTGCCCGGAGCGCTGCGACTGCCAGCATCCCCAGCAT CTCCTGTGCACCAACAGGGGGCTCCGCGTAGTGCCCAAGACCAGCTCGCTGCCGAGCCCC CACGACGTGCTCACCTACAGCCTCGGCGGCAACTTCATAACCAACATCACGGCCTTCGAC TTCCACCGTCTGGGGCAGCTCAGACGGCTGGACCTGCAGTACAACCAGATCCGCTCTCTG CACCCCAAGACCTTCGAGAAGCTCTCGCGGCTGGAAGAGCTGTACCTGGGGAACAACCTC TTGCAGGCGCTCGCCCCGGGCACGCTGGCCCCGCTGCGCAAGCTGCGCATCCTCTACGCC AACGGGAACGAGATCAGCCGCCTAAGCCGCGGCTCCTTCGAGGGCCTGGAGAGTCTAGTC AAGCTGCGGCTGGACGGGAACGCCCTGGGGGCGCTGCCGGACGCGGTCTTCGCTCCCTTG GGCAACCTGCTCTACCTACATCTGGAGTCCAACCGGATCCGCTTTCTGGGCAAGAACGCC TTCGCCCAGCTAGGCAAGCTGCGCTTCCTCAACCTCTCTGCCAACGAGCTACAGCCCTCC CTGCGCCACGCGGCCACCTTCGCACCGCTGCGCTCCCTCTCCTCCCTCATCCTCTCGGCC AACAGCCTGCAGCACCTCGGGCCGCGCATCTTCCAGCACCTGCCACGTCTCGGCCTGCTC TCGCTCAGGGGCAACCAGCTCACGCACCTCGCGCCTGAGGCCTTTTGGGGCTTGGAGGCC CTGCGCGAGCTGCGCCTGGAGGGTAATCGGCTGAGCCAGCTGCCAACTGCGCTGCTGGAG CCTCTGCACAGCCTGGAGGCGCTGGACCTGAGCGGCAATGAGCTGTCCGCCCTGCACCCG GCCACCTTCGGCCACCTGGGCCGGCTGCGCGAGCTCAGCCTGCGCAACAACGCGCTCAGC GCCCTATCCGGGGACATCTTCGCCGCCAGCCCAGCCCTTTATCGGCTGGATCTAGACGGC AACGGCTGGACCTGCGACTGCCGGCTGCGAGGCCTGAAGCGCTGGATGGGCGACTGGCAC TCGCAGGGCCGGCTCCTCACTGTCTTCGTGCAGTGTCGCCACCCCCCGGCCCTGCGAGGC AAATACCTGGATTACCTGGATGACCAGCAGCTGCAAAATGGATCCTGCGCGGATCCCTCG CCCTCAGCTTCCCTGACCGCTGACCGCAGGCGGCAGCCCCTACCCACGGCCGCAGGGGAG GAGATGACGCCACCTGCAGGTCTCGCGGAGGAGCTGCCGCCGCAGCCGCAGCTCCAGCAG CAGGGGCGATTTCTAGCTGGGGTGGCCTGGGATGGGGCCGCCAGGGAGCTGGTAGGCAAC CGCAGCGCTCTAAGGCTGAGTCGGCGGGGCCCGGGCCTCCAGCAGCCCAGCCCCTCCGTC GCTGCCGCCGCGGGCCCGGCTCCACAGTCCCTAGACCTGCACAAGAAGCCCCAGCGGGGC CGTCCGACTCGGGCAGATCCCGCCCTCGCGGAGCCCACCCCAACGGCCTCTCCTGGCTCT GCGCCATCGCCCGCCGGCGACCCCTGGCAGCGCGCGACGAAGCATCGTCTGGGCACGGAG CACCAGGAGCGTGCCGCCCAGTCCGACGGTGGGGCCGGGCTGCCGCCGCTGGTGTCCGAC CCATGCGACTTCAACAAGTTCATTCTGTGCAACCTGACGGTGGAGGCGGTGGGCGCAGAC AGCGCCTCGGTGCGCTGGGCCGTGCGCGAGCACCGCAGTCCCCGGCCGCTGGGCGGCGCG CGCTTCCGCCTGCTCTTTGACCGCTTTGGCCAGCAGCCCAAGTTCCACCGCTTCGTCTAC CTGCCTGAGAGCAGCGACTCGGCCACGCTGCGCGAGCTGCGCGGGGACACCCCCTACCTG GTGTGCGTGGAGGGCGTGCTTGGGGGCCGTGTCTGCCCTGTGGCTCCCCGGGACCACTGC GCGGGGCTGGTCACCCTACCGGAGGCCGGGAGCCGGGGCGGCGTCGACTACCAGCTGCTG ACCTTGGCCCTGCTGACGGTCAACGCGCTGCTGGTGCTCCTGGCCTTGGCGGCCTGGGCG TCTCGCTGGCTGCGTAGGAAACTGCGGGCTAGGCGGAAGGGCGGGGCCCCGGTCCACGTT CGGCACATGTACTCCACCCGACGGCCCCTGCGCTCCATGGGCACCGGCGTGTCCGCCGAC TTCTCGGGATTCCAGTCGCACCGGCCACGCACCACCGTGTGCGCGCTCAGTGAGGCGGAC CTCATCGAATTCCCCTGCGACCGCTTCATGGACAGTGCGGGCGGCGGCGCGGGCGGCAGC CTGAGACGGGAGGACCGTCTCCTGCAGCGATTTGCCGACTACGTAGTTTAAACGAATTCG AGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGC TAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATA ACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATC CGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCA AGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGAC ATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTA GCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGG GCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCA AGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGC ATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTC GGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCA GCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTG CAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTG CTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAG GATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATG CGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGC ATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAA GAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGAT GGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAAT GGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGAC ATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTC CTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTT GACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGCGAAATGACCGACCAAGCGACGCCCAA CCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCA GGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTG CTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGT CAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCC CTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCT TCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTC GTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTA TCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCA GCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAG TGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAG CCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGT AGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAA GATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGG ATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAAT ACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCT TCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACG GTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACC TGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATG GTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCAC GATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGC AGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGAC CCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCAT GCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGC CTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGG AGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATA AACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCT ACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}