Nucleotide Sequence (with vector) for pFN21AA1008
Download
>pFN21AA1008 7489 bp
TCAATATTGGCCATTAGCCATATTATTCATTGGTTATATAGCATAAATCAATATTGGCTA
TTGGCCATTGCATACGTTGTATCTATATCATAATATGTACATTTATATTGGCTCATGTCC
AATATGACCGCCATGTTGGCATTGATTATTGACTAGTTATTAATAGTAATCAATTACGGG
GTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAACTTACGGTAAATGGCCC
GCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCAT
AGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGC
CCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTCCGCCCCCTATTGACGTCAATGA
CGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTACGGGACTTTCCTACTTG
GCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTGATGCGGTTTTGGCAGTACAC
CAATGGGCGTGGATAGCGGTTTGACTCACGGGGATTTCCAAGTCTCCACCCCATTGACGT
CAATGGGAGTTTGTTTTGGCACCAAAATCAACGGGACTTTCCAAAATGTCGTAATAACCC
CGCCCCGTTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATATAAGCAGAGC
TGGTTTAGTGAACCGTCAGATCACTAGAAGCTTTATTGCGGTAGTTTATCACAGTTAAAT
TGCTAACGCAGTCAGTGCTTCTGACACAACAGTCTCGAACTTAAGCTGCAGAAGTTGGTC
GTGAGGCACTGGGCAGGTAAGTATCAAGGTTACAAGACAGGTTTAAGGAGACCAATAGAA
ACTGGGCTTGTCGAGACAGAGAAGACTCTTGCGTTTCTGATAGGCACCTATTGGTCTTAC
TGACATCCACTTTGCCTTTCTCTCCACAGGTGTCCACTCCCAGTTCAATTACAGCTCTTA
AGGCTAGAGTATTAATACGACTCACTATAGGGCTAGCAAAGCCACCATGGCAGAAATCGG
TACTGGCTTTCCATTCGACCCCCATTATGTGGAAGTCCTGGGCGAGCGCATGCACTACGT
CGATGTTGGTCCGCGCGATGGCACCCCTGTGCTGTTCCTGCACGGTAACCCGACCTCCTC
CTACGTGTGGCGCAACATCATCCCGCATGTTGCACCGACCCATCGCTGCATTGCTCCAGA
CCTGATCGGTATGGGCAAATCCGACAAACCAGACCTGGGTTATTTCTTCGACGACCACGT
CCGCTTCATGGATGCCTTCATCGAAGCCCTGGGTCTGGAAGAGGTCGTCCTGGTCATTCA
CGACTGGGGCTCCGCTCTGGGTTTCCACTGGGCCAAGCGCAATCCAGAGCGCGTCAAAGG
TATTGCATTTATGGAGTTCATCCGCCCTATCCCGACCTGGGACGAATGGCCAGAATTTGC
CCGCGAGACCTTCCAGGCCTTCCGCACCACCGACGTCGGCCGCAAGCTGATCATCGATCA
GAACGTTTTTATCGAGGGTACGCTGCCGATGGGTGTCGTCCGCCCGCTGACTGAAGTCGA
GATGGACCATTACCGCGAGCCGTTCCTGAATCCTGTTGACCGCGAGCCACTGTGGCGCTT
CCCAAACGAGCTGCCAATCGCCGGTGAGCCAGCGAACATCGTCGCGCTGGTCGAAGAATA
CATGGACTGGCTGCACCAGTCCCCTGTCCCGAAGCTGCTGTTCTGGGGCACCCCAGGCGT
TCTGATCCCACCGGCCGAAGCCGCTCGCCTGGCCAAAAGCCTGCCTAACTGCAAGGCTGT
GGACATCGGCCCGGGTCTGAATCTGCTGCAAGAAGACAACCCGGACCTGATCGGCAGCGA
GATCGCGCGCTGGCTGTCGACGCTCGAGATTTCCGGCGAGCCAACCACTGAGGATCTGTA
CTTTCAGAGCGATAACGCGATCGCCATGCTCAAGTCCAAGACGTTCTTAAAAAAGACCCG
GGCGGGCGGCGTGATGAAGATCGTGCGCGAGCACTACCTGCGAGACGACATCGGCTGCGG
TGCGCCCGGGTGCGCAGCGTGTGGAGGGGCGCACGAGGGGCCGGCCCTGGAGCCGCAGCC
CCAGGACCCGGCGAGCAGCGTCTGCCCGCAACCGCACTACTTGCTGCCCGACACTAATGT
GTTACTGCACCAGATTGTAAGTGCCTGGAGGCCGGGGACCTGGGCTTCTGTGGCCTCCAG
CCTGCGACTCCCAGGCAGCTTAGAAACCTATGTAGAACAAGAACAGGGAGAAAATGCTAA
TGACAGGAATGATAGAGCGATTCGAGTAGCAGCAAAATGGTACAATGAACATTTGAAAAA
AATGTCAGCAGACAACCAGCTGCAAGTTATCTTCATAACAAATGACAGGAGAAACAAAGA
GAAAGCCATAGAAGAAGGAATACCAGCTTTCACTTGTGAAGAATATGTAAAGAGCCTAAC
TGCTAACCCCGAACTCATAGATCGTCTTGCTTGTTTGTCTGAAGAAGGGAATGAAATAGA
AAGTGGAAAAATAATATTTTCAGAGCATCTTCCCTTAAGTAAGCTACAGCAAGGCATAAA
ATCTGGTACATACCTTCAAGGAACATTTAGAGCTAGCAGGGAAAATTACTTGGAAGCTAC
AGTATGGATTCATGGCGACAATGAAGAAAATAAAGAGATAATCTTACAGGGACTTAAACA
TTTAAACAGAGCTGTTCACGAAGATATTGTGGCTGTGGAGCTTCTCCCCAAGAGTCAGTG
GGTAGCACCATCTTCTGTGGTTTTACATGATGAAGGTCAAAATGAAGAAGATGTGGAGAA
AGAAGAAGAGAGAGAACGAATGCTTAAGACTGCTGTAAGCGAGAAAATGTTGAAGCCTAC
AGGTAGAGTTGTAGGAATAATAAAAAGGAATTGGAGACCATATTGTGGCATGCTTTCCAA
GTCTGACATTAAGGAGTCAAGAAGACATCTCTTTACACCTGCTGATAAGAGAATCCCTCG
AATTCGCATAGAAACCAGACAGGCTTCCACATTAGAAGGACGGAGAATTATTGTTGCTAT
TGATGGTTGGCCCAGAAATTCCAGATATCCAAATGGACACTTTGTGAGAAATTTAGGTGA
TGTTGGAGAGAAAGAGACTGAAACAGAAGTTTTGTTACTTGAACACGATGTTCCCCATCA
GCCTTTTTCACAGGCTGTTCTTAGTTTTCTGCCAAAGATGCCCTGGAGCATTACTGAAAA
GGACATGAAAAACCGAGAAGACCTGAGGCATCTGTGTATTTGTAGTGTAGACCCACCAGG
ATGTACTGATATAGACGATGCTCTACATTGTCGAGAACTCGAAAATGGAAATTTGGAGGT
TGGTGTTCATATTGCTGATGTGAGCCATTTTATTAGGCCAGGAAATGCCTTGGATCAAGA
ATCAGCCAGAAGAGGAACAACTGTGTATCTTTGTGAAAAGAGGATTGACATGGTTCCAGA
GTTGCTTAGCTCTAACTTGTGTTCCTTAAAATGTGACGTGGACAGGCTGGCATTTTCATG
TATTTGGGAAATGAATCACAATGCTGAAATCTTAAAAACGAAGTTTACCAAAAGTGTTAT
TAATTCAAAGGCATCTCTGACATATGCTGAAGCTCAGTTGAGAATTGATTCAGCAAACAT
GAATGATGATATTACCACTAGTCTCCGTGGACTGAATAAACTAGCCAAAATTCTGAAGAA
AAGAAGGATTGAAAAAGGGGCTTTGACTCTATCCTCTCCTGAAGTTCGATTCCACATGGA
CAGTGAAACTCACGATCCTATAGATCTGCAGACCAAGGAACTTAGGGAAACAAATTCCAT
GGTTGAAGAATTTATGTTACTTGCCAATATTTCTGTTGCAAAAAAAATTCATGAGGAATT
TTCTGAACATGCTCTGCTTCGAAAACATCCTGCTCCACCTCCATCAAATTATGAAATTCT
TGTTAAGGCAGCCAGGTCAAGGAATTTGGAAATTAAGACTGATACAGCCAAGTCTTTGGC
TGAGTCTTTGGATCAGGCCGAATCTCCTACTTTTCCATATCTAAACACTCTGTTGAGAAT
ATTAGCCACTCGCTGTATGATGCAAGCTGTGTACTTCTGTTCTGGAATGGATAATGATTT
TCATCACTATGGCTTAGCGTCTCCAATATACACACATTTTACTTCACCCATTAGAAGATA
CGCAGATGTCATTGTTCATCGGCTTTTGGCTGTGGCTATTGGGGCTGACTGTACTTATCC
AGAGTTGACAGACAAACACAAGCTTGCAGATATATGTAAAAATCTAAATTTCCGGCACAA
AATGGCTCAATATGCCCAACGTGCATCAGTGGCTTTTCATACCCAGTTATTCTTCAAAAG
CAAAGGAATAGTAAGTGAAGAAGCCTATATTTTATTTGTAAGAAAGAATGCCATTGTGGT
ATTAATTCCAAAGTATGGTTTAGAAGGGACAGTCTTTTTTGAAGAAAAGGACAAACCAAA
CCCACAGCTTATTTATGATGATGAGATACCCTCACTTAAAATAGAAGATACAGTGTTCCA
TGTATTTGATAAAGTTAAAGTGAAAATCATGTTAGACTCATCTAATCTTCAACATCAGAA
GATCCGAATGTCCCTGGTAGAACCACAGATACCAGGAATAAGCATTCCTACTGATACTTC
AAACATGGACCTTAATGGACCAAAGAAAAAGAAGATGAAGCTTGGAAAAGTTTAAACGAA
TTCGGGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGG
CTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAG
CATAACCCCTTGGGGCGGCCGCTTCGAGCAGACATGATAAGATACATTGATGAGTTTGGA
CAAACCACAACTAGAATGCAGTGAAAAAAATGCTTTATTTGTGAAATTTGTGATGCTATT
GCTTTATTTGTAACCATTATAAGCTGCAATAAACAAGTTAACAACAACAATTGCATTCAT
TTTATGTTTCAGGTTCAGGGGGAGATGTGGGAGGTTTTTTTAAGCAAGTAAAACCTCTAC
AAATGTGGTAAAATCGAATTCTAATGGATCCTCTTTGCGCTTGCGTTTTCCCTTGTCCAG
ATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTAC
GTAATGGTTTCTTAGACGTCAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATT
TGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAGACAATAACCCTGATAA
ATGCTTCAATAATATTGAAAAAGGAAGAGTATGAGTATTCAACATTTCCGTGTCGCCCTT
ATTCCCTTTTTTGCGGCATTTTGCCTTCCTGTTTTTGCTCACCCAGAAACGCTGGTGAAA
GTAAAAGATGCTGAAGATCAGTTGGGTGCACGAGTGGGTTACATCGAACTGGATCTCAAC
AGCGGTAAGATCCTTGAGAGTTTTCGCCCCGAAGAACGTTTTCCAATGATGAGCACTTTC
AAAGTTCTGCTATGTGGCGCGGTATTATCCCGTATTGACGCCGGGCAAGAGCAACTCGGT
CGCCGCATACACTATTCTCAGAATGACTTGGTTGAGTACTCACCAGTCACAGAAAAGCAT
CTTACGGATGGCATGACAGTAAGAGAATTATGCAGTGCTGCCATAACCATGAGTGATAAC
ACTGCGGCCAACTTACTTCTGACAACTATCGGAGGACCGAAGGAGCTAACCGCTTTTTTG
CACAACATGGGGGATCATGTAACTCGCCTTGATCGTTGGGAACCGGAGCTGAATGAAGCC
ATACCAAACGACGAGCGTGACACCACGATGCCTGTAGCAATGGCAACAACGTTGCGCAAA
CTATTAACTGGCGAACTACTTACTCTAGCTTCCCGGCAACAATTAATAGACTGGATGGAG
GCGGATAAAGTTGCAGGACCACTTCTGCGCTCGGCCCTTCCGGCTGGCTGGTTTATTGCT
GATAAATCTGGAGCCGGTGAGCGTGGGTCTCGCGGTATCATTGCAGCACTGGGGCCAGAT
GGTAAGCCCTCCCGTATCGTAGTTATCTACACGACGGGGAGTCAGGCAACTATGGATGAA
CGAAATAGACAGATCGCTGAGATAGGTGCCTCACTGATTAAGCATTGGTAATTCGAAATG
ACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCA
CAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGA
ACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATC
ACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGG
CGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGAT
ACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGT
ATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTC
AGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACG
ACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCG
GTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTG
GTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCG
GCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCA
GAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGA
ACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGA
TCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGA
AACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTG
GTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGT
GGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTG
CGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATA
AACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCT



 Characterization of the cloned ORF
Characterization of the cloned ORF Restriction map B
Restriction map B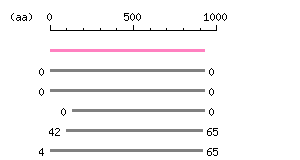
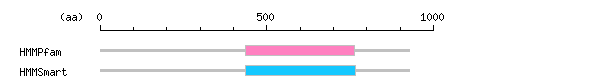
 more Linker info
more Linker info

{kind=link}